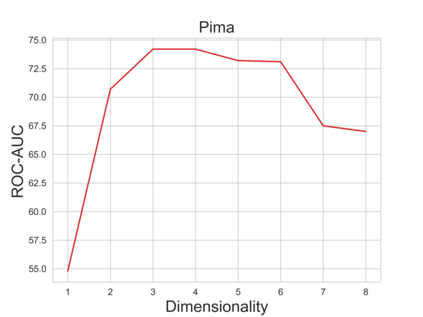
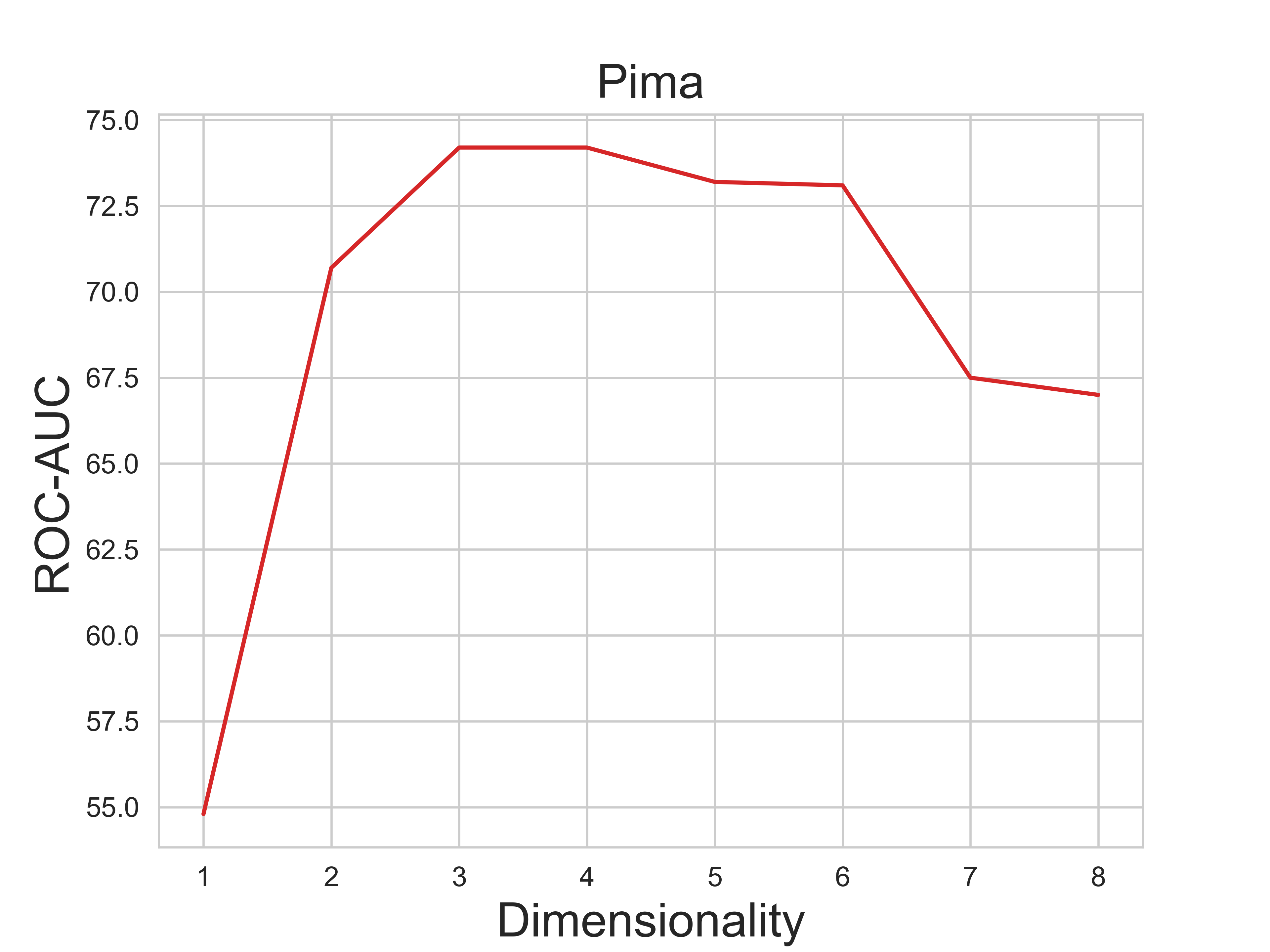
Anomaly detection methods, powered by deep learning, have recently been making significant progress, mostly due to improved representations. It is tempting to hypothesize that anomaly detection can improve indefinitely by increasing the scale of our networks, making their representations more expressive. In this paper, we provide theoretical and empirical evidence to the contrary. In fact, we empirically show cases where very expressive representations fail to detect even simple anomalies when evaluated beyond the well-studied object-centric datasets. To investigate this phenomenon, we begin by introducing a novel theoretical toy model for anomaly detection performance. The model uncovers a fundamental trade-off between representation sufficiency and over-expressivity. It provides evidence for a no-free-lunch theorem in anomaly detection stating that increasing representation expressivity will eventually result in performance degradation. Instead, guidance must be provided to focus the representation on the attributes relevant to the anomalies of interest. We conduct an extensive empirical investigation demonstrating that state-of-the-art representations often suffer from over-expressivity, failing to detect many types of anomalies. Our investigation demonstrates how this over-expressivity impairs image anomaly detection in practical settings. We conclude with future directions for mitigating this issue.
翻译:暂无翻译