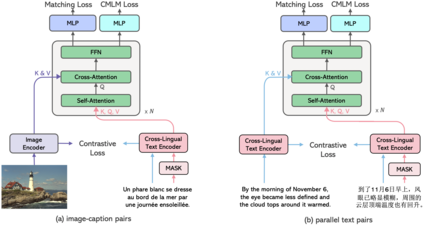
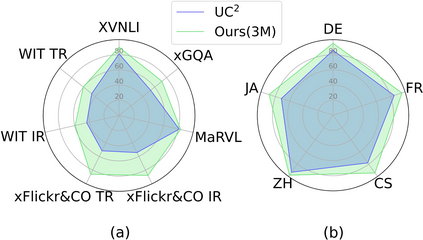
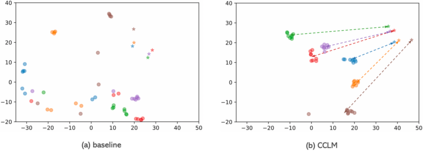
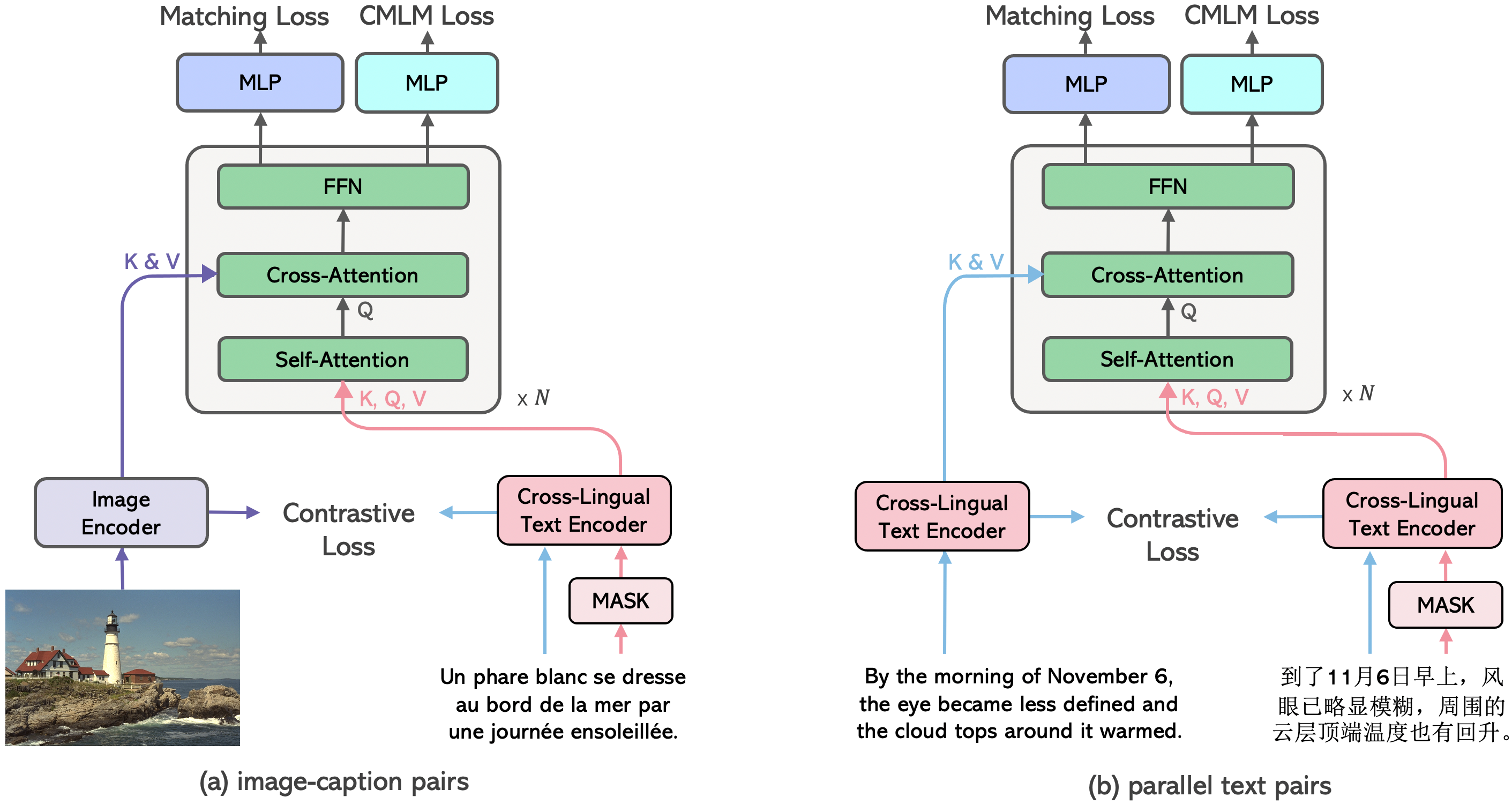
In this paper, we introduce Cross-View Language Modeling, a simple and effective language model pre-training framework that unifies cross-lingual cross-modal pre-training with shared architectures and objectives. Our approach is motivated by a key observation that cross-lingual and cross-modal pre-training share the same goal of aligning two different views of the same object into a common semantic space. To this end, the cross-view language modeling framework considers both multi-modal data (i.e., image-caption pairs) and multi-lingual data (i.e., parallel sentence pairs) as two different views of the same object, and trains the model to align the two views by maximizing the mutual information between them with conditional masked language modeling and contrastive learning. We pre-train CCLM, a Cross-lingual Cross-modal Language Model, with the cross-view language modeling framework. Empirical results on IGLUE, a multi-lingual multi-modal benchmark, and two multi-lingual image-text retrieval datasets show that while conceptually simpler, CCLM significantly outperforms the prior state-of-the-art with an average absolute improvement of over 10%. Notably, CCLM is the first multi-lingual multi-modal model that surpasses the translate-test performance of representative English vision-language models by zero-shot cross-lingual transfer.
翻译:在本文中,我们引入了跨语言建模,这是一个简单而有效的语言建模模式培训前示范框架,将跨语言跨模式培训前的跨语言培训与共同的架构和目标统一起来,我们的方法的动机是:跨语言和跨模式培训前的培训前的跨语言和跨模式培训有着将同一对象的两种不同观点统一到一个共同的语义空间的相同目标。为此,交叉语言建模框架将多模式数据(即图像成像配对)和多语言数据(即平行句对)作为同一对象的两种不同观点,并培训该模式,通过最大限度地利用有条件的蒙面语言建模和对比性学习,使这两种观点相互信息最大化。我们预先设计CCLM,一个跨语言跨语言跨模式的跨模式的跨模式语言语言语言语言建模框架,一个多语言的多模式基准,以及两个多语言的图像检索数据集(即平行配对)显示,在概念上更简单、CCLM绝对的跨语言翻版多语言的多语言模式上,比先前的多语言建模前多语言建模。