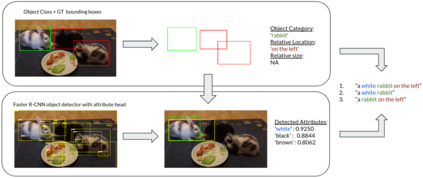
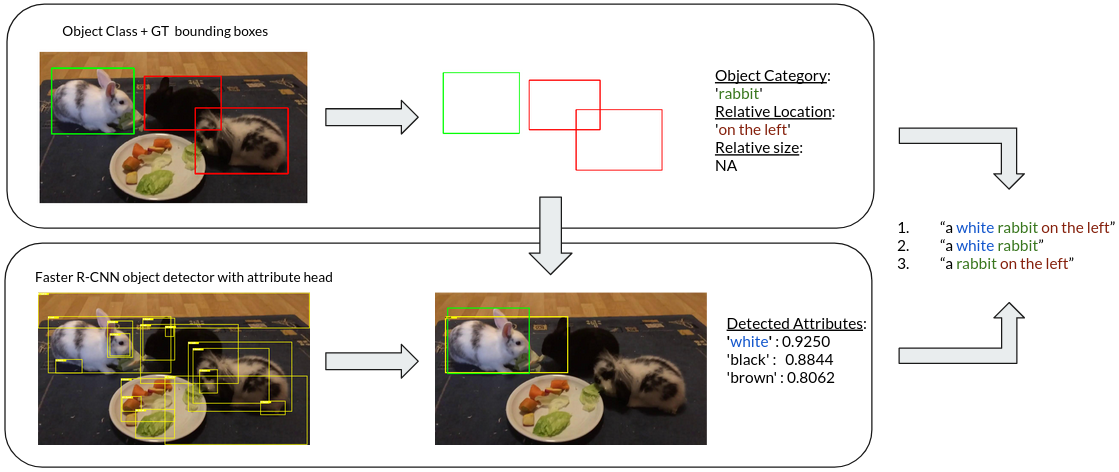
Recent advances in deep learning have brought significant progress in visual grounding tasks such as language-guided video object segmentation. However, collecting large datasets for these tasks is expensive in terms of annotation time, which represents a bottleneck. To this end, we propose a novel method, namely SynthRef, for generating synthetic referring expressions for target objects in an image (or video frame), and we also present and disseminate the first large-scale dataset with synthetic referring expressions for video object segmentation. Our experiments demonstrate that by training with our synthetic referring expressions one can improve the ability of a model to generalize across different datasets, without any additional annotation cost. Moreover, our formulation allows its application to any object detection or segmentation dataset.
翻译:最近深层学习的进展在视觉定位任务(如语言引导视频对象分割)方面取得了显著进展。然而,为这些任务收集大型数据集的费用在批注时间方面是昂贵的,这是一个瓶颈。为此,我们提出一种新的方法,即合成参考法,用于生成图像(或视频框)中目标物体的合成参考表达法,我们还展示和传播第一个包含视频对象分割合成参考表达法的大型数据集。我们的实验表明,通过对合成参考表达法的培训,人们可以提高模型的能力,在不增加任何注释成本的情况下,将不同数据集综合起来。此外,我们的配方允许将其应用于任何对象探测或分割数据集。