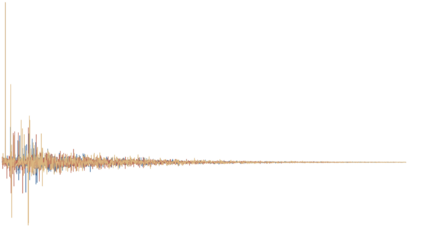
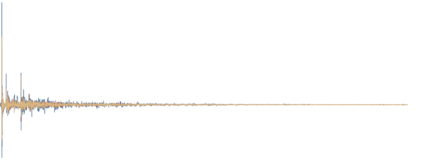
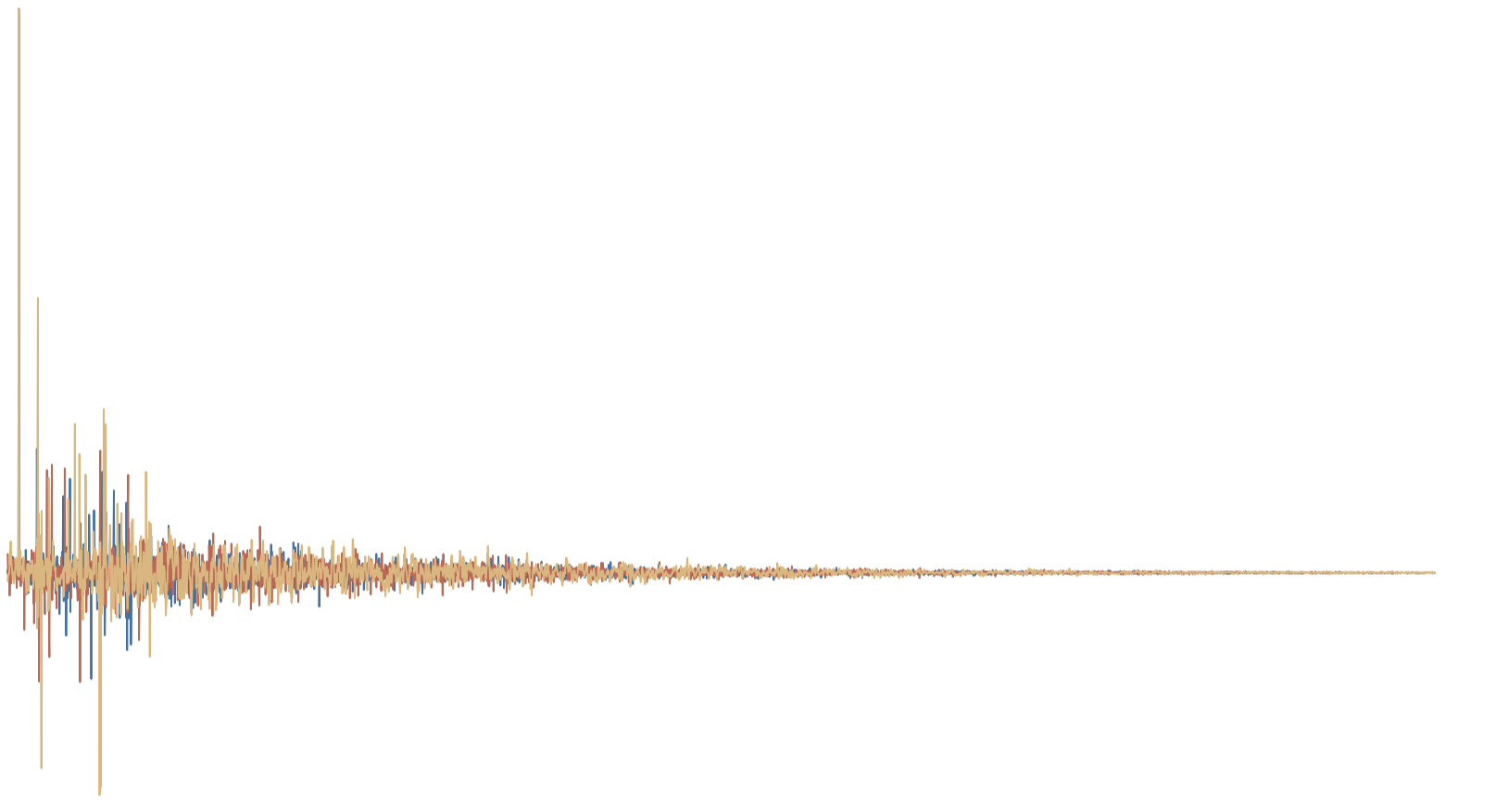
The classification of acoustic environments allows for machines to better understand the auditory world around them. The use of deep learning in order to teach machines to discriminate between different rooms is a new area of research. Similarly to other learning tasks, this task suffers from the high-dimensionality and the limited availability of training data. Data augmentation methods have proven useful in addressing this issue in the tasks of sound event detection and scene classification. This paper proposes a method for data augmentation for the task of room classification from reverberant speech. Generative Adversarial Networks (GANs) are trained that generate artificial data as if they were measured in real rooms. This provides additional training examples to the classifiers without the need for any additional data collection, which is time-consuming and often impractical. A representation of acoustic environments is proposed, which is used to train the GANs. The representation is based on a sparse model for the early reflections, a stochastic model for the reverberant tail and a mixing mechanism between the two. In the experiments shown, the proposed data augmentation method increases the test accuracy of a CNN-RNN room classifier from 89.4% to 95.5%.
翻译:声学环境的分类使得机器能够更好地了解周围的听觉世界。使用深层次的学习来教机器区分不同房间是一个新的研究领域。与其他学习任务一样,这项任务也因高维度和培训数据有限而受到影响。数据增强方法已证明有助于在健全的事件探测和场景分类任务中解决这一问题。本文件建议了一种方法,用于从回声讲话中增加房间分类任务的数据。 基因反转网络(GAN)经过培训,产生人工数据,如同在真实房间里测量数据一样。这为分类者提供了额外的培训实例,而无需收集任何额外的数据,而这种数据耗费时间,而且往往不切实际。提出了用于培训GAN的声学环境的表述。该表述基于一种稀疏的早期反省模型、一种回动尾和两种之间混合机制的随机分析模型。在所显示的实验中,拟议的数据增强方法提高了CNN-RNN室分类器的测试精度,从89.4%提高到95.5%。