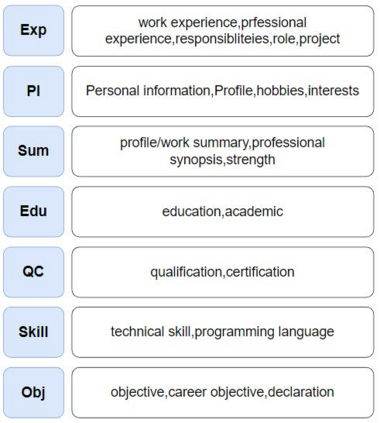
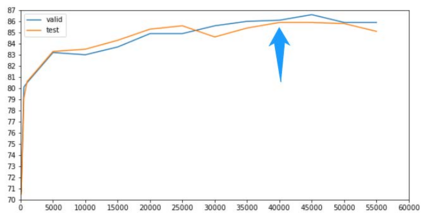
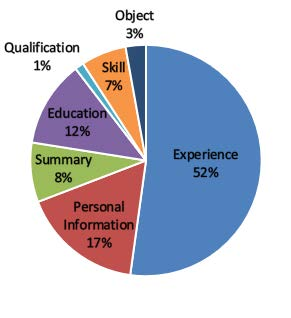
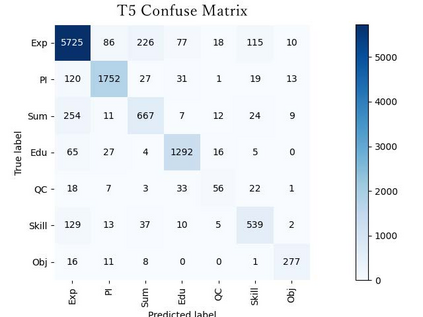
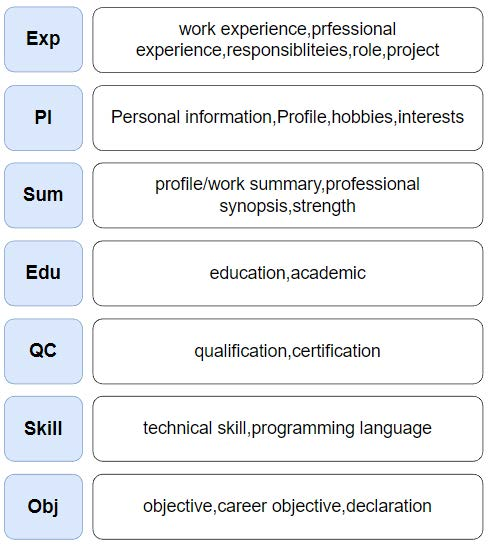
Information extraction(IE) has always been one of the essential tasks of NLP. Moreover, one of the most critical application scenarios of information extraction is the information extraction of resumes. Constructed text is obtained by classifying each part of the resume. It is convenient to store these texts for later search and analysis. Furthermore, the constructed resume data can also be used in the AI resume screening system. Significantly reduce the labor cost of HR. This study aims to transform the information extraction task of resumes into a simple sentence classification task. Based on the English resume dataset produced by the prior study. The classification rules are improved to create a larger and more fine-grained classification dataset of resumes. This corpus is also used to test some current mainstream Pre-training language models (PLMs) performance.Furthermore, in order to explore the relationship between the number of training samples and the correctness rate of the resume dataset, we also performed comparison experiments with training sets of different train set sizes.The final multiple experimental results show that the resume dataset with improved annotation rules and increased sample size of the dataset improves the accuracy of the original resume dataset.
翻译:信息提取(IE)一直是NLP的基本任务之一。 此外,信息提取的最关键应用情景之一是信息提取的信息提取。 构建文本是通过对恢复的每个部分进行分类而获得的。 保存这些文本便于以后进行搜索和分析。 此外, 构建的恢复数据也可以用于AI 恢复筛选系统。 大幅降低人力资源的人工成本。 这项研究的目的是将恢复的信息提取任务转换成简单的句子分类任务。 根据先前的研究产生的英语恢复数据集, 分类规则得到改进, 以创建更大规模、更精细的恢复的分类数据集。 该功能还用于测试当前的主流培训前语言模型(PLMS)的性能。 此外, 为了探索培训样本的数量与恢复数据集的准确率之间的关系, 我们还进行了与不同列车设置大小的培训数据集的比较试验。 最后的多次实验结果表明,恢复数据集改进了说明规则,并增加了数据集的样本大小,提高了原始恢复数据集的准确性。