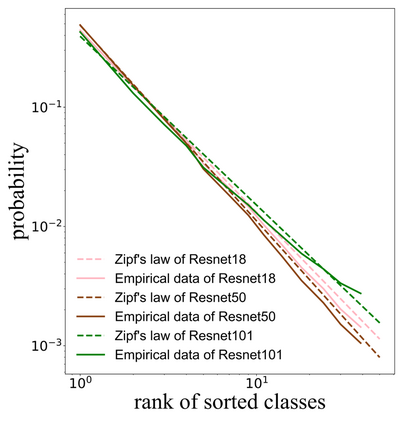
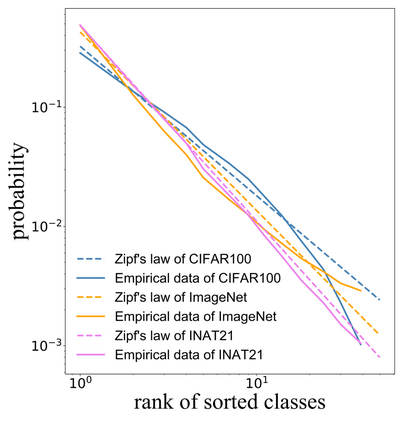
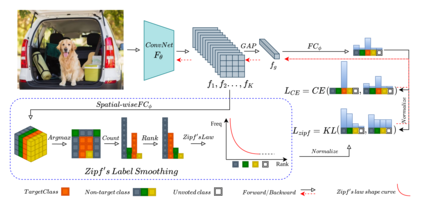
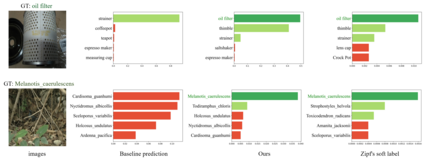
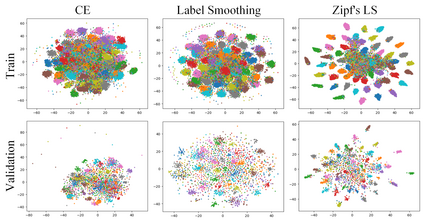
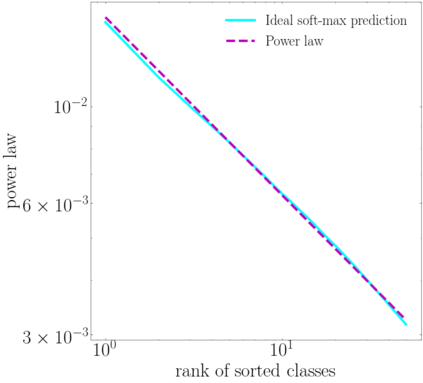
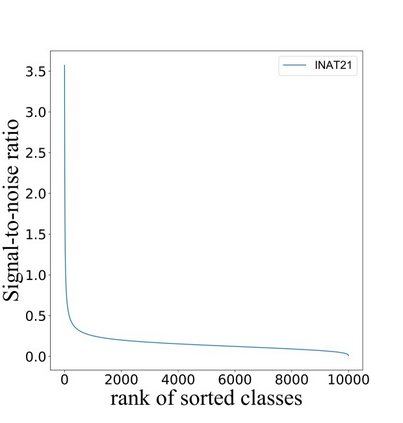
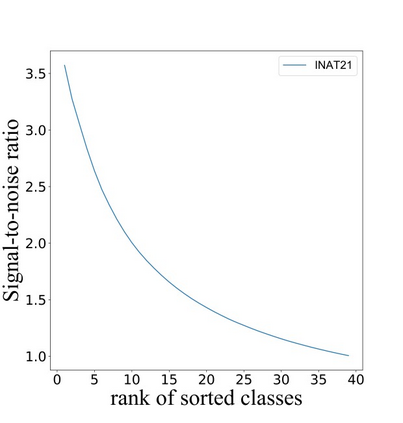
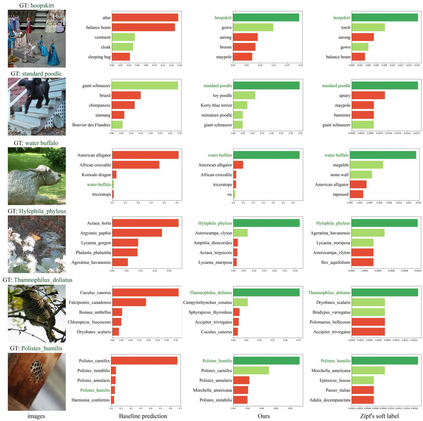
Self-distillation exploits non-uniform soft supervision from itself during training and improves performance without any runtime cost. However, the overhead during training is often overlooked, and yet reducing time and memory overhead during training is increasingly important in the giant models' era. This paper proposes an efficient self-distillation method named Zipf's Label Smoothing (Zipf's LS), which uses the on-the-fly prediction of a network to generate soft supervision that conforms to Zipf distribution without using any contrastive samples or auxiliary parameters. Our idea comes from an empirical observation that when the network is duly trained the output values of a network's final softmax layer, after sorting by the magnitude and averaged across samples, should follow a distribution reminiscent to Zipf's Law in the word frequency statistics of natural languages. By enforcing this property on the sample level and throughout the whole training period, we find that the prediction accuracy can be greatly improved. Using ResNet50 on the INAT21 fine-grained classification dataset, our technique achieves +3.61% accuracy gain compared to the vanilla baseline, and 0.88% more gain against the previous label smoothing or self-distillation strategies. The implementation is publicly available at https://github.com/megvii-research/zipfls.
翻译:自我蒸馏利用培训过程中的不统一软性监督,在不花费任何运行时间的情况下提高性能。 但是,培训期间的间接费用往往被忽视,而培训期间的减少时间和记忆管理在巨型模型时代越来越重要。 本文建议了一种名为 Zipf 的 Label 光滑( Zipf 的 LS) 的有效自我蒸馏方法, 使用网络的实时预测, 产生与Zipf 分布相一致的软性监督, 而没有使用任何对比样本或辅助参数。 我们的想法来自一项经验观测, 即当网络在对网络最后软质层的产出值进行适当培训时, 在按照大小和平均的样本排序后, 培训过程中的时间和记忆管理时间和记忆管理在培训过程中越来越重要。 通过在样本级别和整个培训期间执行这一特性, 我们发现预测的准确性可以大大改进。 在INAT21 精细分类数据集上使用 ResNet50, 我们的技术在对网络最后软质层层进行适当培训后, 经过对网络最后软质层的输出值进行校准后, 在自然语言的频率统计上实现了+3.81%/revb 的精确度, 我们的技术在前的自我定位上取得了上, 。