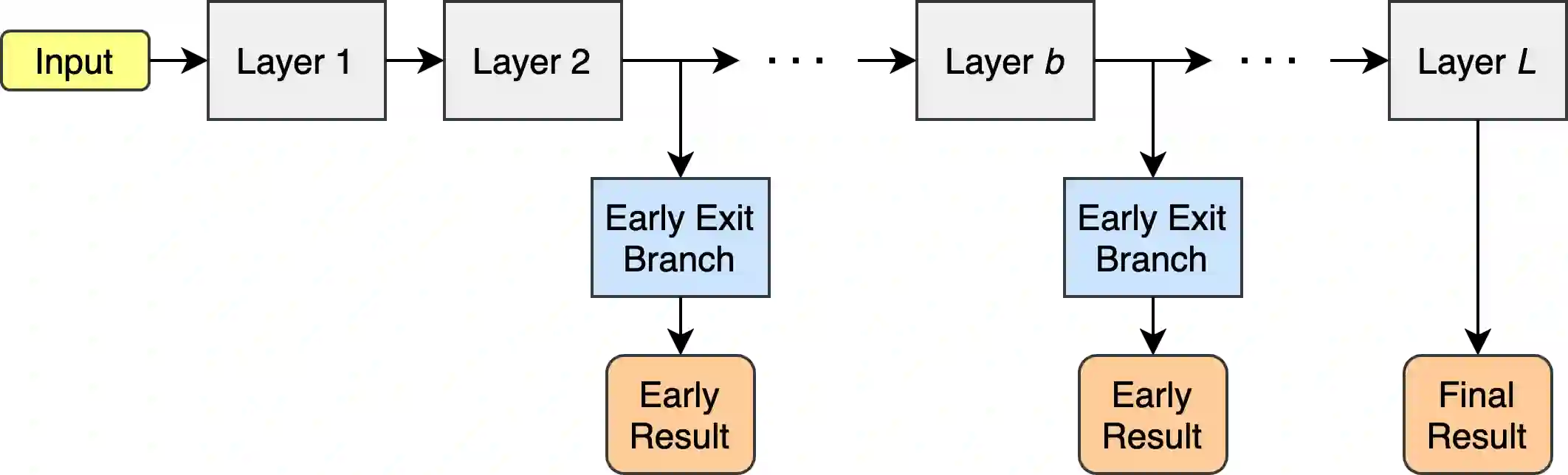
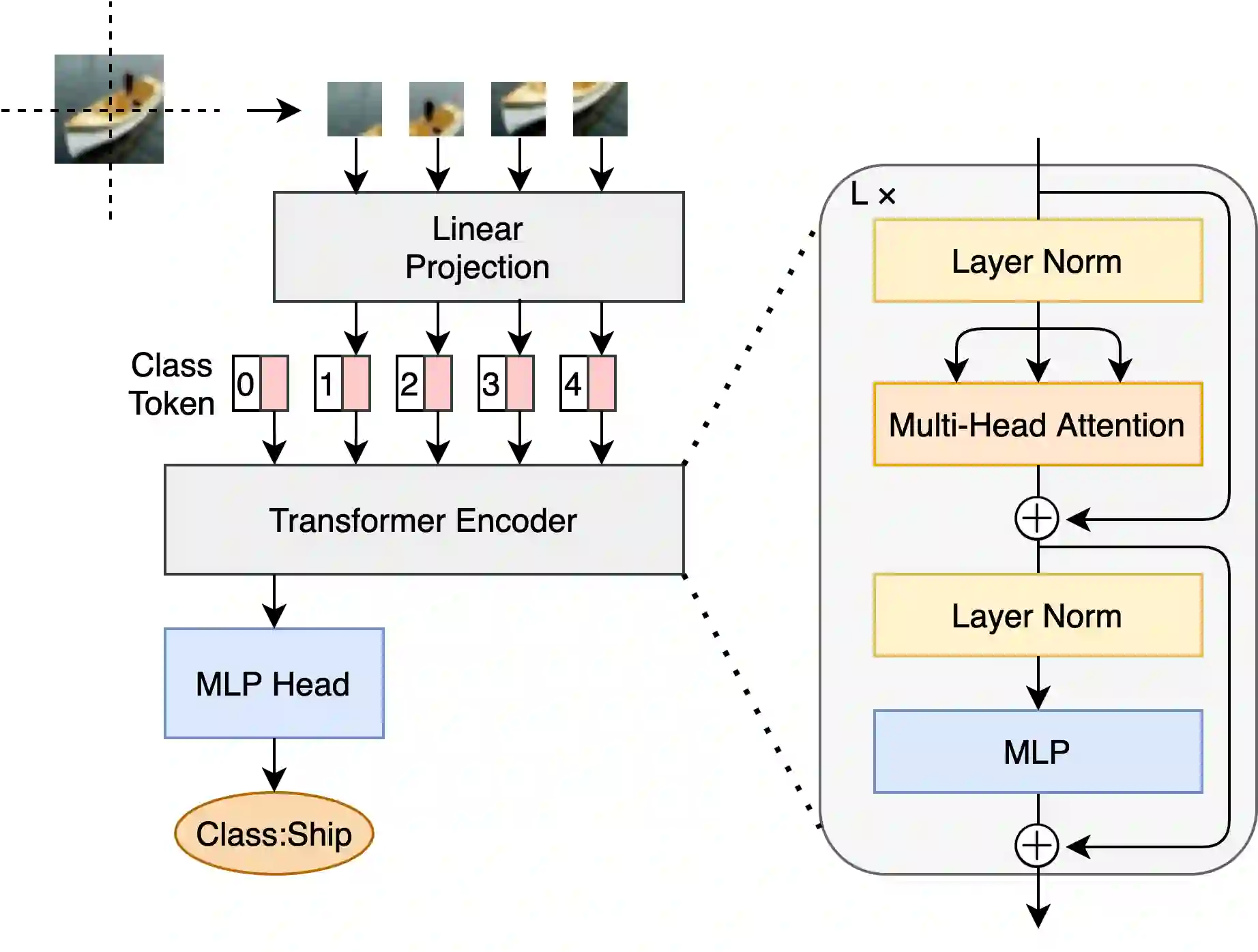
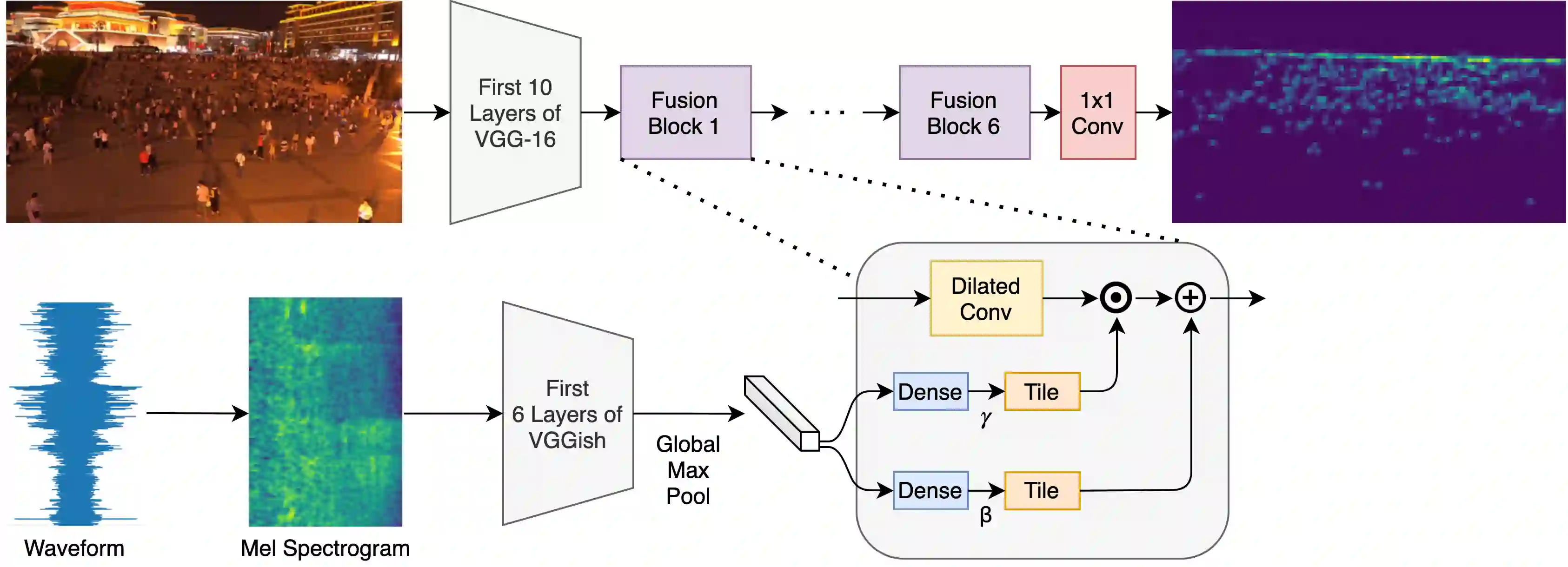
Deploying deep learning models in time-critical applications with limited computational resources, for instance in edge computing systems and IoT networks, is a challenging task that often relies on dynamic inference methods such as early exiting. In this paper, we introduce a novel architecture for early exiting based on the vision transformer architecture, as well as a fine-tuning strategy that significantly increase the accuracy of early exit branches compared to conventional approaches while introducing less overhead. Through extensive experiments on image and audio classification as well as audiovisual crowd counting, we show that our method works for both classification and regression problems, and in both single- and multi-modal settings. Additionally, we introduce a novel method for integrating audio and visual modalities within early exits in audiovisual data analysis, that can lead to a more fine-grained dynamic inference.
翻译:在具有有限计算资源的时间临界应用中,例如在边缘计算系统和IoT网络中,部署深度学习模型,是一项具有挑战性的任务,往往依赖动态推论方法,如提前退出。 在本文中,我们引入了基于愿景变压器结构的早期退出新架构,以及一项微调战略,与常规方法相比,大大提高早期退出分支的准确性,同时采用较少的管理费用。 通过对图像和音频分类以及视听人群计数的广泛实验,我们发现我们的方法在分类和回归问题以及单一和多模式环境中都起作用。 此外,我们引入了一种在视听数据分析早期输出中整合视听和视觉模式的新方法,这可以导致更精细的动态推论。