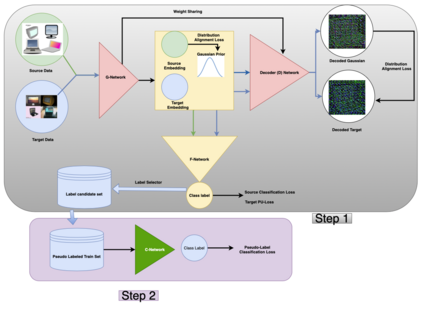
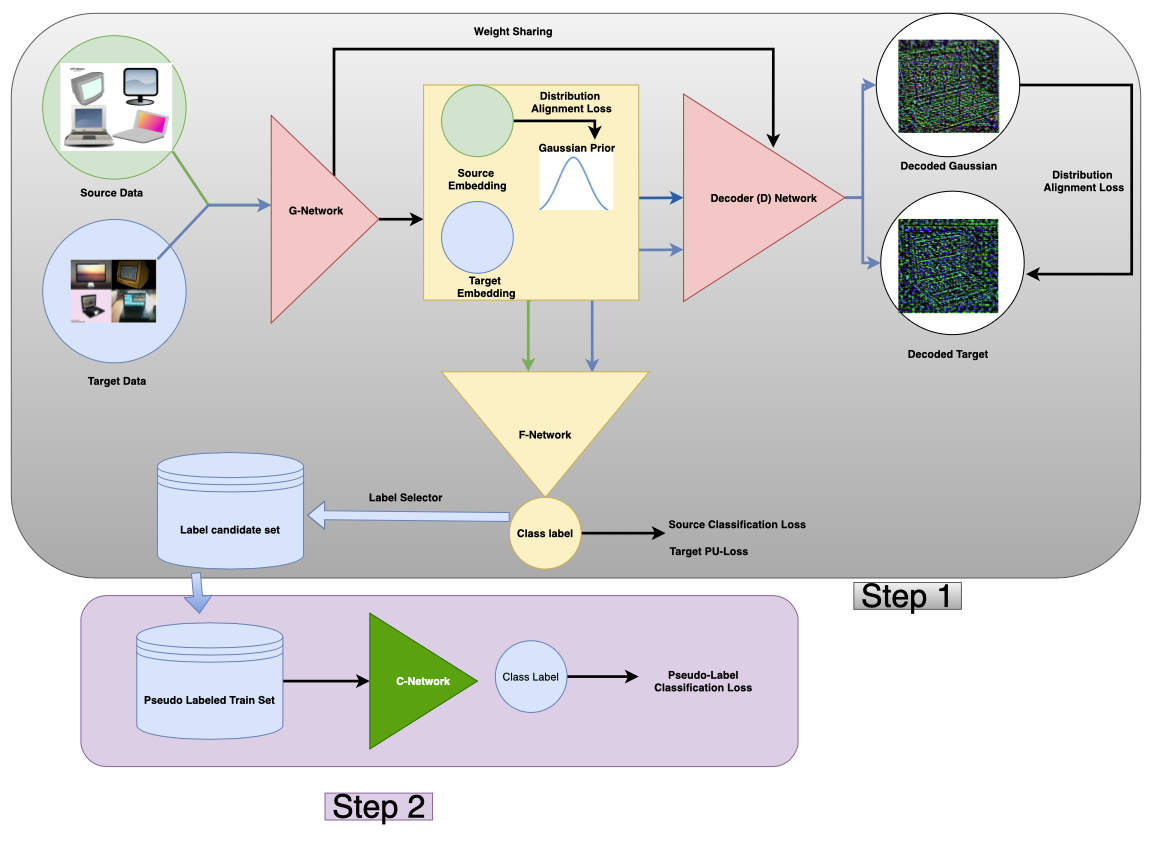
Domain Adaptation methodologies have shown to effectively generalize from a labeled source domain to a label scarce target domain. Previous research has either focused on unlabeled domain adaptation without any target supervision or semi-supervised domain adaptation with few labeled target examples per class. On the other hand Positive-Unlabeled (PU-) Learning has attracted increasing interest in the weakly supervised learning literature since in quite some real world applications positive labels are much easier to obtain than negative ones. In this work we are the first to introduce the challenge of Positive-Unlabeled Domain Adaptation where we aim to generalise from a fully labeled source domain to a target domain where only positive and unlabeled data is available. We present a novel two-step learning approach to this problem by firstly identifying reliable positive and negative pseudo-labels in the target domain guided by source domain labels and a positive-unlabeled risk estimator. This enables us to use a standard classifier on the target domain in a second step. We validate our approach by running experiments on benchmark datasets for visual object recognition. Furthermore we propose real world examples for our setting and validate our superior performance on parking occupancy data.
翻译:域适应方法显示, 能够有效地从标签源域向标签稀缺的目标域范围推广。 先前的研究要么侧重于无标签域适应, 没有任何目标监督, 要么半监督域适应, 每一类少几个标签目标示例。 另一方面, 积极- 无标签( PU) 学习吸引了人们对监管不力的学习文献的兴趣, 因为在某些真实世界中, 积极性标签比消极性标签更容易获得。 在这项工作中, 我们首先引入了正- 无标签域适应的挑战, 我们打算将完全标签源域推广到仅提供正性和无标签数据的目标域。 我们提出一个新的两步学习方法, 首先在目标域中确定可靠的正和负伪标签, 由源域名标签和正- 无标签风险估计器指导。 这使我们能够在第二步中在目标域使用标准分类器。 我们验证我们的方法, 其方法是在视觉对象识别的基准数据集上进行实验。 此外, 我们提出真实的世界范例, 用于我们设置和验证我们在泊车位数据上的高级性表现。