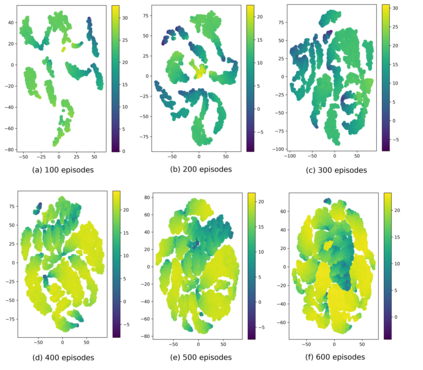
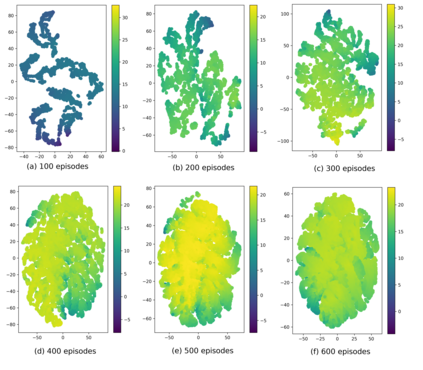
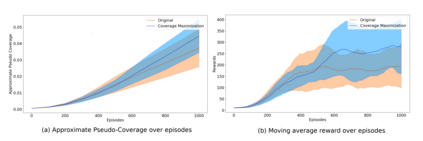
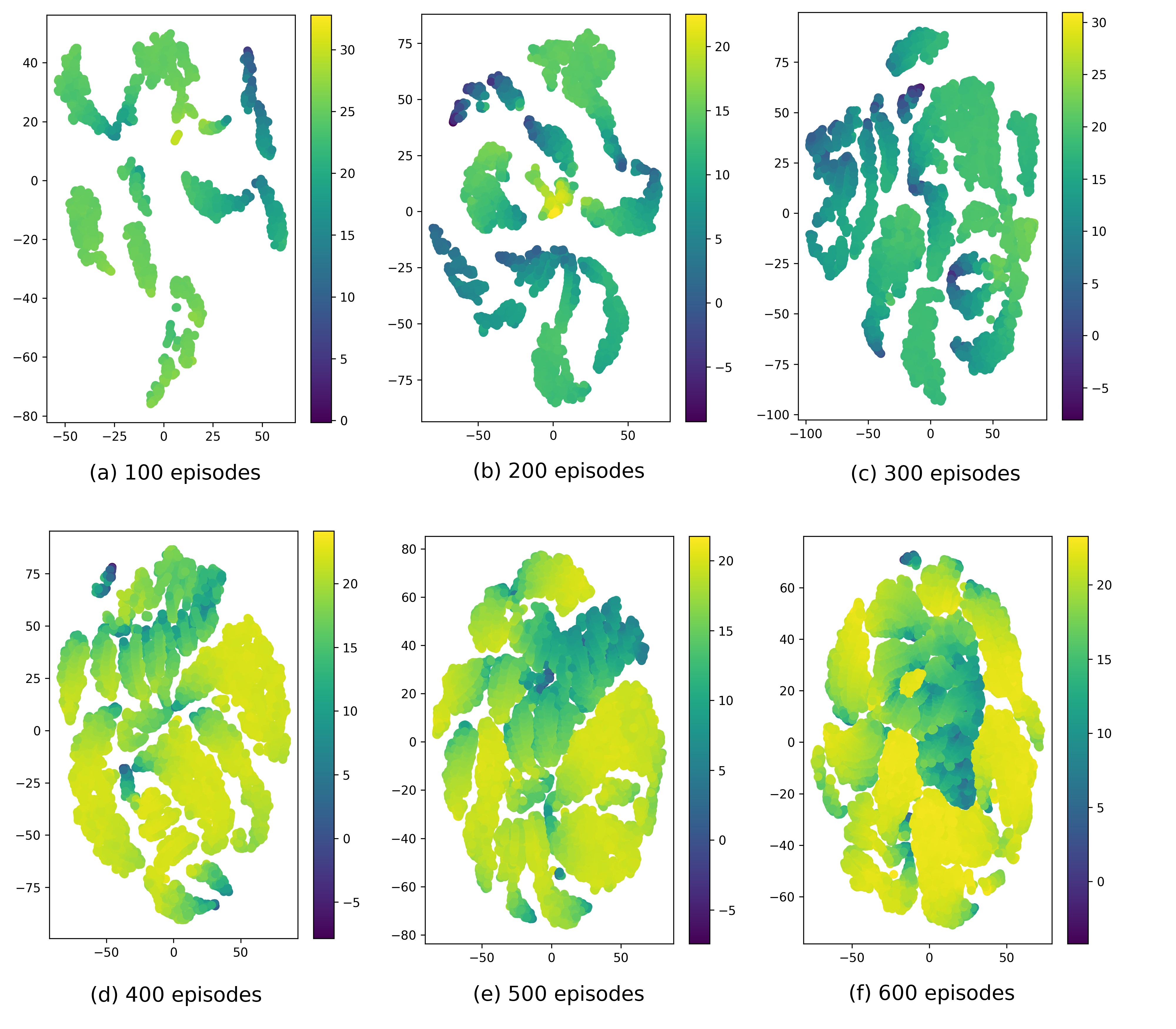
Current deep reinforcement learning (DRL) algorithms utilize randomness in simulation environments to assume complete coverage in the state space. However, particularly in high dimensions, relying on randomness may lead to gaps in coverage of the trained DRL neural network model, which in turn may lead to drastic and often fatal real-world situations. To the best of the author's knowledge, the assessment of coverage for DRL is lacking in current research literature. Therefore, in this paper, a novel measure, Approximate Pseudo-Coverage (APC), is proposed for assessing the coverage in DRL applications. We propose to calculate APC by projecting the high dimensional state space on to a lower dimensional manifold and quantifying the occupied space. Furthermore, we utilize an exploration-exploitation strategy for coverage maximization using Rapidly-Exploring Random Tree (RRT). The efficacy of the assessment and the acceleration of coverage is demonstrated on standard tasks such as Cartpole, highway-env.
翻译:目前深入强化学习(DRL)算法利用模拟环境中的随机性来完全覆盖国家空间,但是,特别是在高度方面,依赖随机性可能导致经过训练的DRL神经网络模型覆盖面的缺口,而这反过来又可能导致急剧和往往是致命的现实世界情况。据作者所知,目前研究文献中缺乏对DRL覆盖面的评估。因此,本文件提议采用新颖措施Apbiright Pseudo-Coverage(APC)来评估DRL应用的覆盖范围。我们提议通过预测高维空间在较低维度的方位上并对所占空间进行量化来计算APC。此外,我们利用探索利用快速开发随机树(RRT)进行覆盖最大化的探索利用战略。评估的功效和覆盖范围的加速程度在卡托尔、高速公路-env等标准任务上得到了证明。