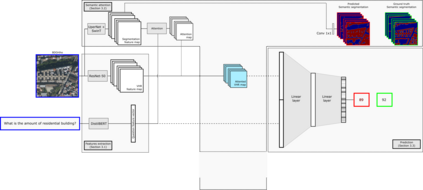
Visual Question Answering for Remote Sensing (RSVQA) is a task that aims at answering natural language questions about the content of a remote sensing image. The visual features extraction is therefore an essential step in a VQA pipeline. By incorporating attention mechanisms into this process, models gain the ability to focus selectively on salient regions of the image, prioritizing the most relevant visual information for a given question. In this work, we propose to embed an attention mechanism guided by segmentation into a RSVQA pipeline. We argue that segmentation plays a crucial role in guiding attention by providing a contextual understanding of the visual information, underlying specific objects or areas of interest. To evaluate this methodology, we provide a new VQA dataset that exploits very high-resolution RGB orthophotos annotated with 16 segmentation classes and question/answer pairs. Our study shows promising results of our new methodology, gaining almost 10% of overall accuracy compared to a classical method on the proposed dataset.
翻译:暂无翻译