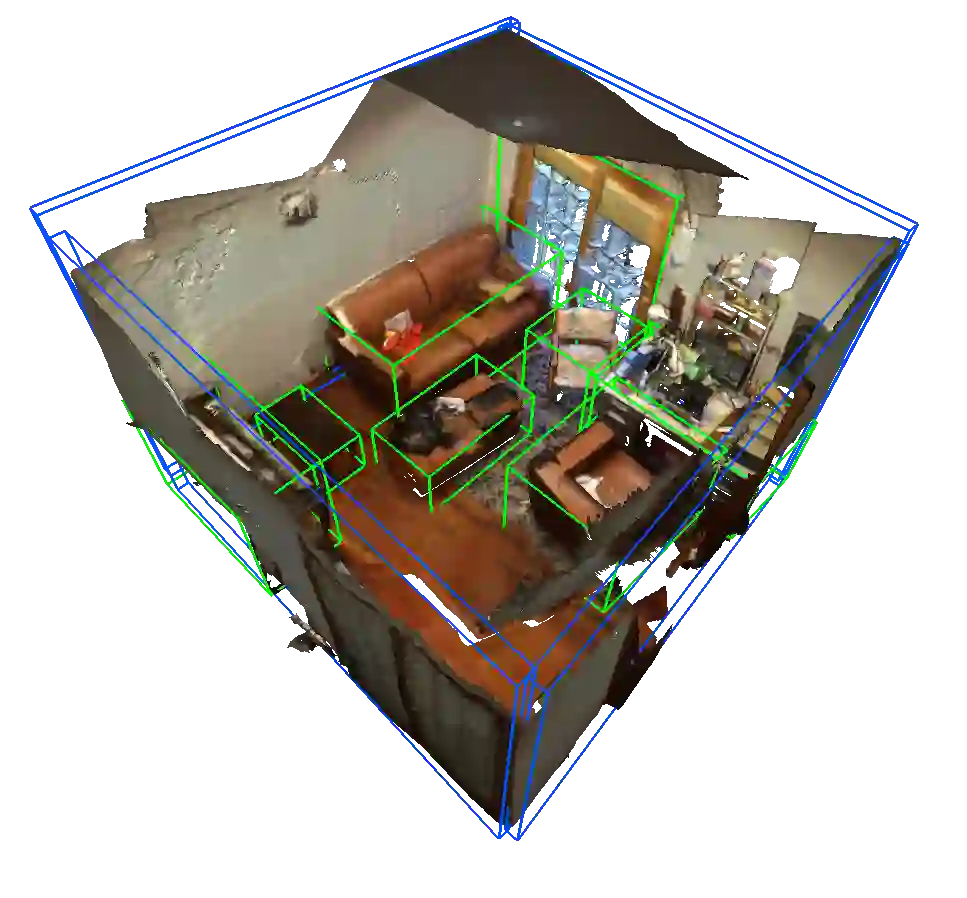
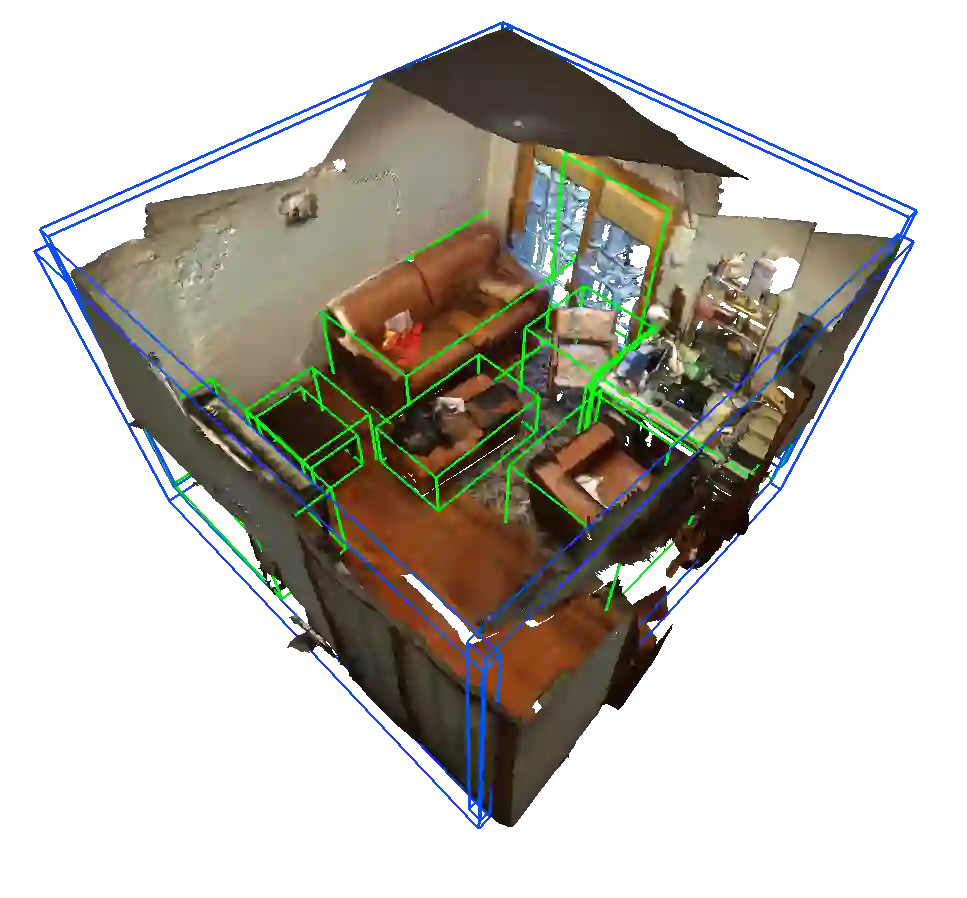
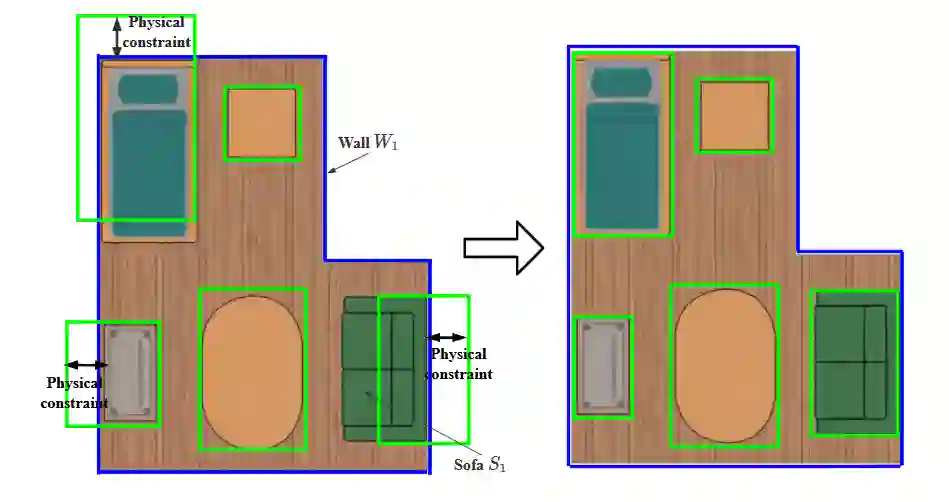
3D scene understanding from point clouds plays a vital role for various robotic applications. Unfortunately, current state-of-the-art methods use separate neural networks for different tasks like object detection or room layout estimation. Such a scheme has two limitations: 1) Storing and running several networks for different tasks are expensive for typical robotic platforms. 2) The intrinsic structure of separate outputs are ignored and potentially violated. To this end, we propose the first transformer architecture that predicts 3D objects and layouts simultaneously, using point cloud inputs. Unlike existing methods that either estimate layout keypoints or edges, we directly parameterize room layout as a set of quads. As such, the proposed architecture is termed as P(oint)Q(uad)-Transformer. Along with the novel quad representation, we propose a tailored physical constraint loss function that discourages object-layout interference. The quantitative and qualitative evaluations on the public benchmark ScanNet show that the proposed PQ-Transformer succeeds to jointly parse 3D objects and layouts, running at a quasi-real-time (8.91 FPS) rate without efficiency-oriented optimization. Moreover, the new physical constraint loss can improve strong baselines, and the F1-score of the room layout is significantly promoted from 37.9% to 57.9%.
翻译:来自点云的3D场景理解在各种机器人应用中起着关键作用。 不幸的是,目前最先进的方法在物体探测或房间布局估计等不同任务中使用了单独的神经网络。 这样的计划有两个局限性:(1) 典型的机器人平台对不同任务的存储和运行几个网络费用昂贵。 (2) 单独产出的内在结构被忽视,并有可能被破坏。 为此,我们提议了第一个同时预测3D对象和布局的变压器结构, 使用点云输入。 与现有的方法不同的是, 要么估计布局关键点或边缘, 我们直接将房间布局参数作为一组四分。 因此, 提议的架构被称为 P(oint)Q(Uad)- Transformod。 与新型的四分代表相比, 我们提出了一个有针对性的物理约束性损失功能, 抑制了物体外延干扰。 公共基准扫描网的定量和定性评价显示, 拟议的PQ- Extraxent 成功联合分析3D对象和布局, 运行在准实时( 891 FPS) 的速率( 69) 和无效率优化。 此外, 新的物理约束能大大改进了57.9% 的F.9% 的基底压强基线和F. 9。