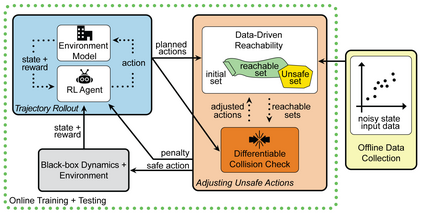
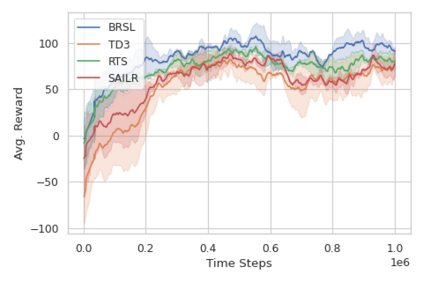
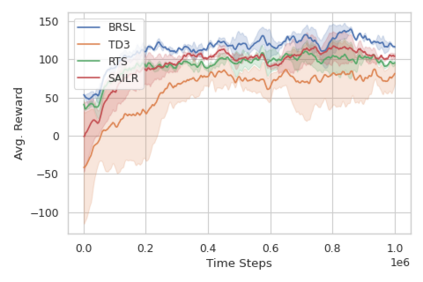
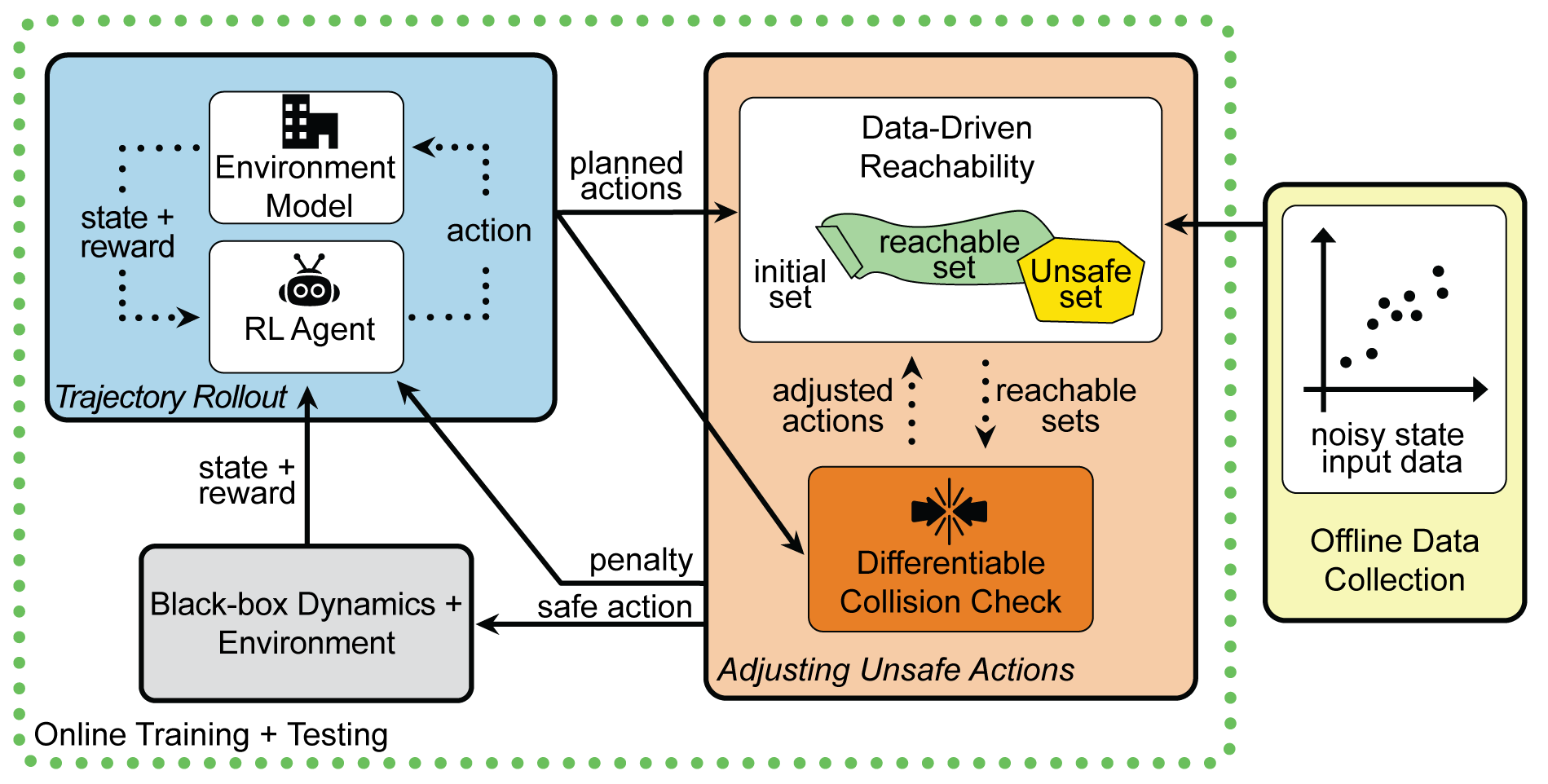
Reinforcement learning (RL) is capable of sophisticated motion planning and control for robots in uncertain environments. However, state-of-the-art deep RL approaches typically lack safety guarantees, especially when the robot and environment models are unknown. To justify widespread deployment, robots must respect safety constraints without sacrificing performance. Thus, we propose a Black-box Reachability-based Safety Layer (BRSL) with three main components: (1) data-driven reachability analysis for a black-box robot model, (2) a trajectory rollout planner that predicts future actions and observations using an ensemble of neural networks trained online, and (3) a differentiable polytope collision check between the reachable set and obstacles that enables correcting unsafe actions. In simulation, BRSL outperforms other state-of-the-art safe RL methods on a Turtlebot 3, a quadrotor, and a trajectory-tracking point mass with an unsafe set adjacent to the area of highest reward.
翻译:强化学习(RL)能够对不确定环境中的机器人进行复杂的运动规划和控制,然而,最先进的深层RL方法通常缺乏安全保障,特别是当机器人和环境模型未知时。为了证明广泛部署的理由,机器人必须尊重安全限制而不牺牲性能。因此,我们提议采用基于黑箱的安全层(BRSL),该安全层有三个主要组成部分:(1) 黑箱机器人模型的数据驱动可达性分析,(2) 利用经过在线培训的神经网络组合预测未来行动和观测的轨迹推出计划,(3) 对可到达的集和能够纠正不安全行动的障碍进行不同的多点碰撞检查。 在模拟中,BRSLS在Turtlebot 3号、Quadrortor和轨迹跟踪点质量上优于最有报酬的不安全区域。