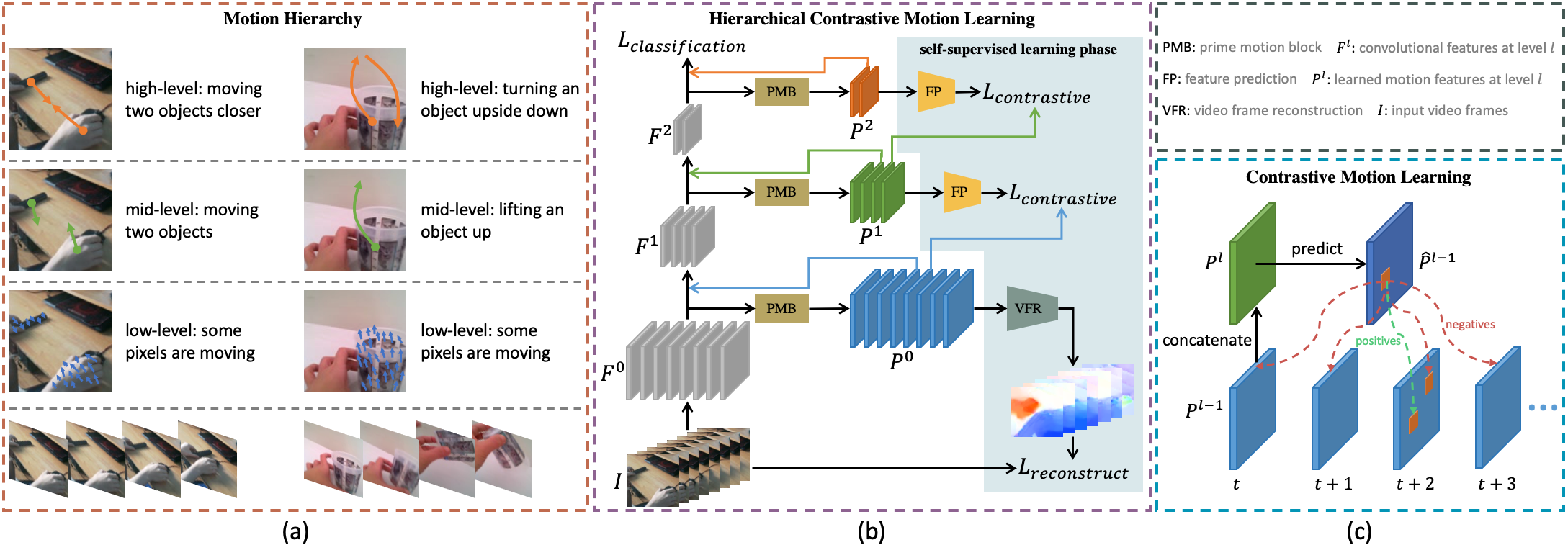
One central question for video action recognition is how to model motion. In this paper, we present hierarchical contrastive motion learning, a new self-supervised learning framework to extract effective motion representations from raw video frames. Our approach progressively learns a hierarchy of motion features that correspond to different abstraction levels in a network. This hierarchical design bridges the semantic gap between low-level motion cues and high-level recognition tasks, and promotes the fusion of appearance and motion information at multiple levels. At each level, an explicit motion self-supervision is provided via contrastive learning to enforce the motion features at the current level to predict the future ones at the previous level. Thus, the motion features at higher levels are trained to gradually capture semantic dynamics and evolve more discriminative for action recognition. Our motion learning module is lightweight and flexible to be embedded into various backbone networks. Extensive experiments on four benchmarks show that the proposed approach consistently achieves superior results.
翻译:视频动作识别的一个中心问题是如何模拟运动。 在本文中,我们展示了分级对比运动学习,这是一个新的自我监督的学习框架,以从原始视频框中提取有效的运动演示。我们的方法逐渐学习了与网络中不同抽象层次相对应的运动特征的等级。这种等级设计将低层次运动提示和高级认知任务之间的语义差距连接起来,促进多层次的外观和运动信息的融合。在每一级,通过对比学习提供明确的运动自我监督观点,以在目前的层次上执行运动特征,预测前一级的未来特征。因此,更高层次的运动特征受过培训,以逐渐捕捉语义动态,并进化更具有歧视性的行动识别。我们的运动学习模块是轻量和灵活的,可以嵌入各种骨干网络。关于四个基准的广泛实验表明,拟议的方法始终能取得优异的结果。