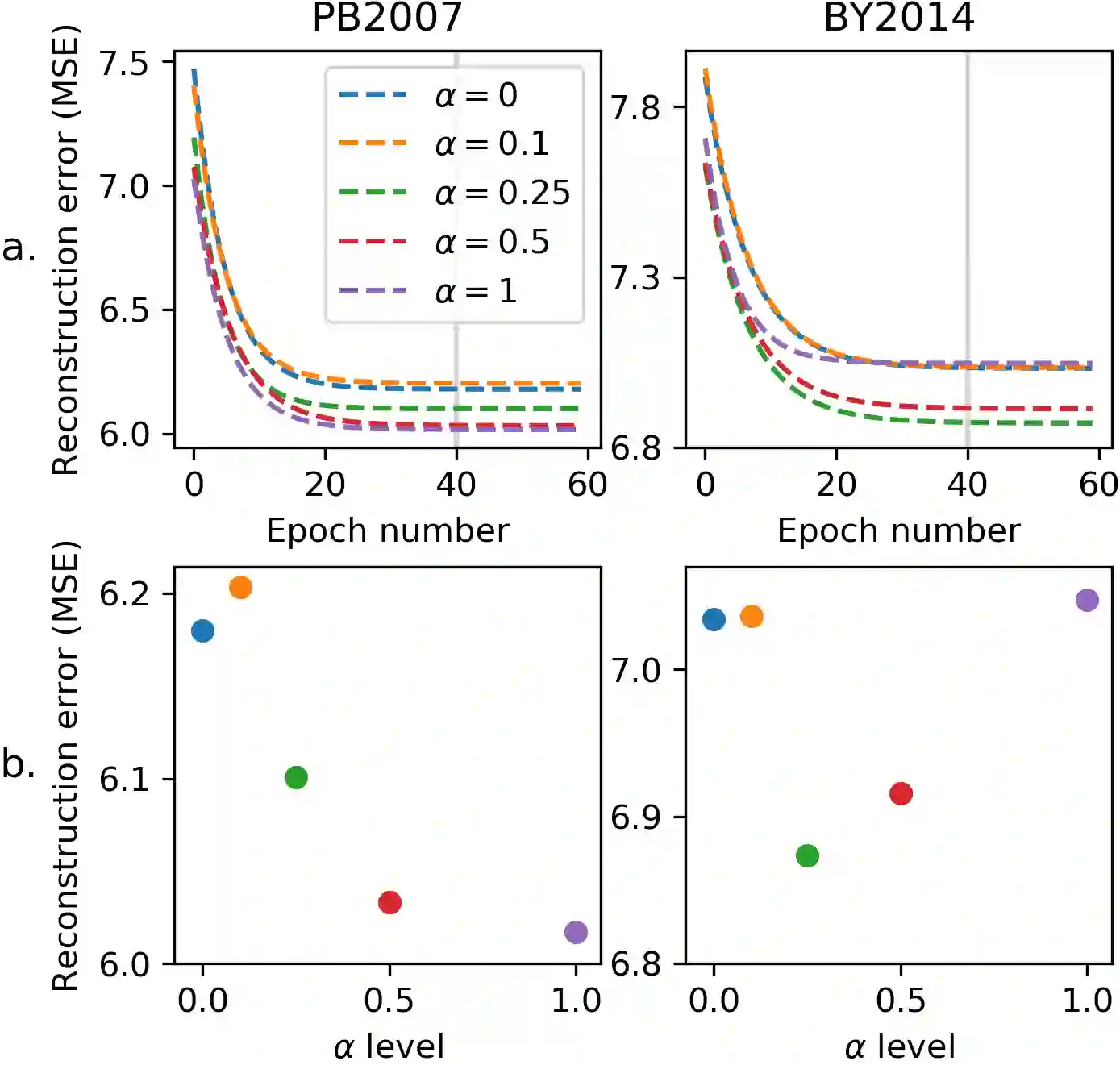
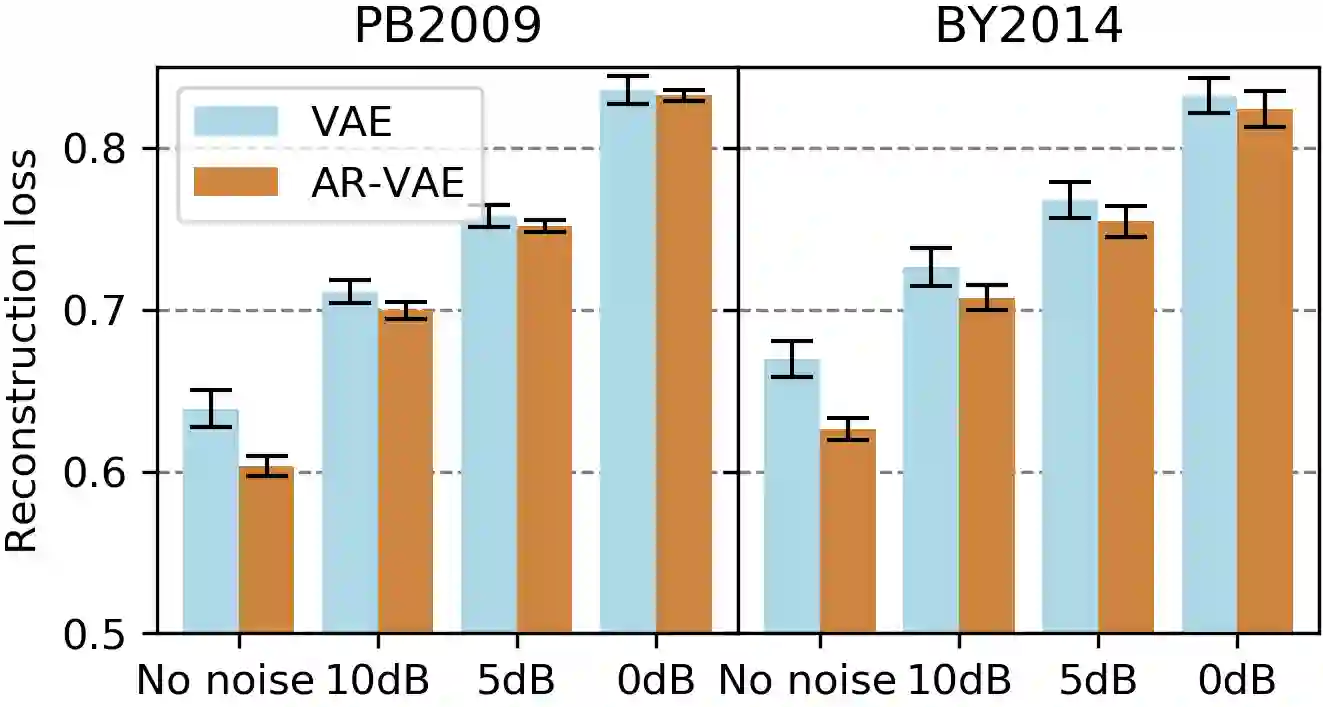
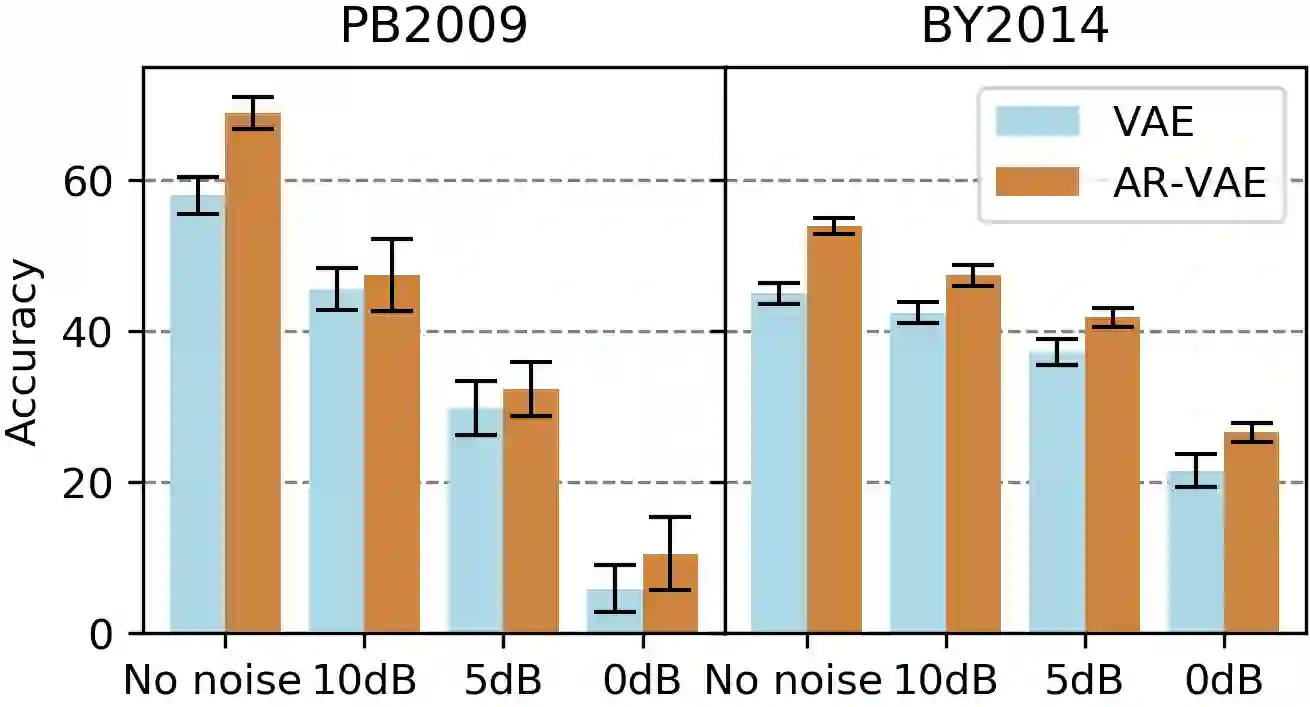
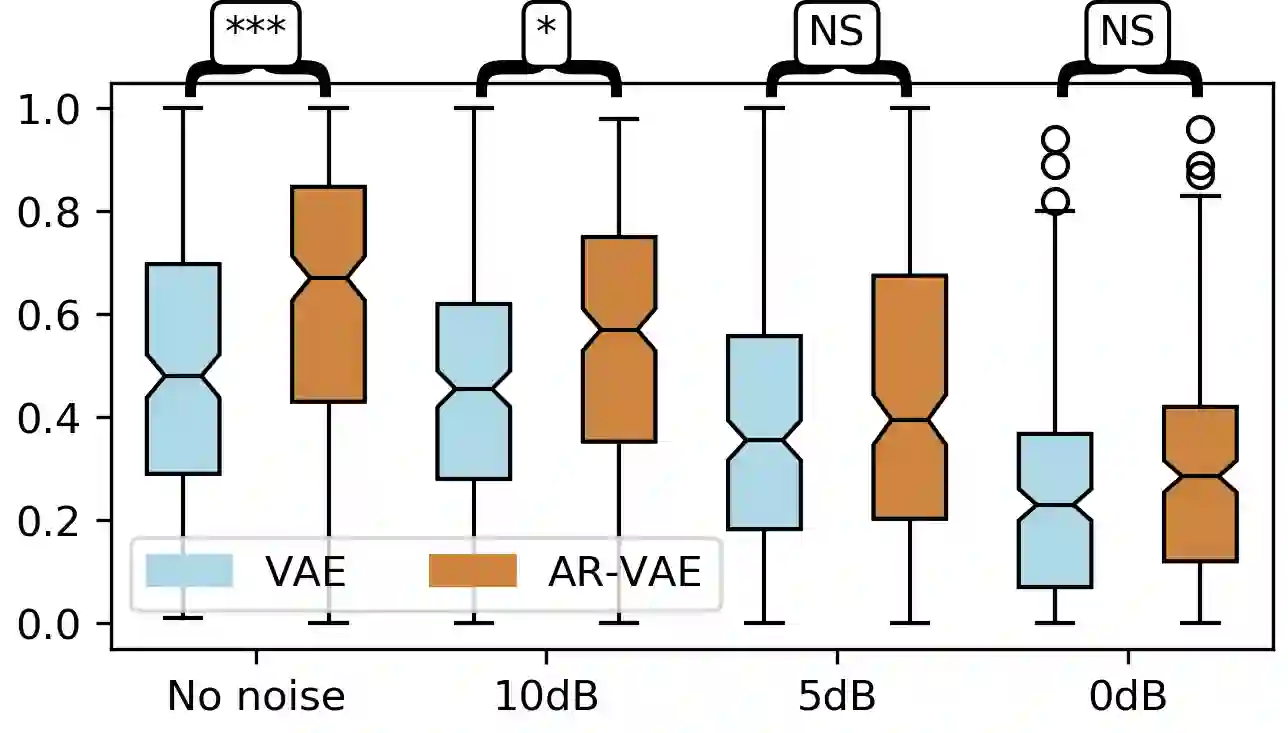
It is increasingly considered that human speech perception and production both rely on articulatory representations. In this paper, we investigate whether this type of representation could improve the performances of a deep generative model (here a variational autoencoder) trained to encode and decode acoustic speech features. First we develop an articulatory model able to associate articulatory parameters describing the jaw, tongue, lips and velum configurations with vocal tract shapes and spectral features. Then we incorporate these articulatory parameters into a variational autoencoder applied on spectral features by using a regularization technique that constraints part of the latent space to follow articulatory trajectories. We show that this articulatory constraint improves model training by decreasing time to convergence and reconstruction loss at convergence, and yields better performance in a speech denoising task.
翻译:人们日益认识到,人类的言语感知和制作都依赖于动脉表征。在本文中,我们调查这种表征是否能够改善深层基因模型(这里是一个可变自动编码器)的性能,该模型经过了对声调特征进行编码和解码的培训。首先,我们开发了一种动脉模型,能够将描述下巴、舌头、嘴唇和排卵管配置的动脉参数与声道形状和光谱特征联系起来。然后,我们将这些动脉参数纳入对光谱特征应用的变异自动编码器中,使用一种正规化技术,限制潜在空间的一部分以跟踪动脉道轨迹。我们表明,这种动脉冲制约通过缩短时间以趋同和在趋同时重建损耗来改进模式培训,并在语言解析任务中产生更好的性能。