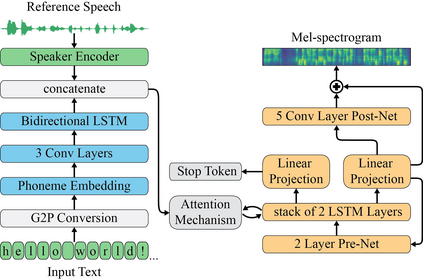
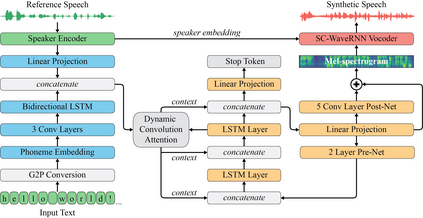
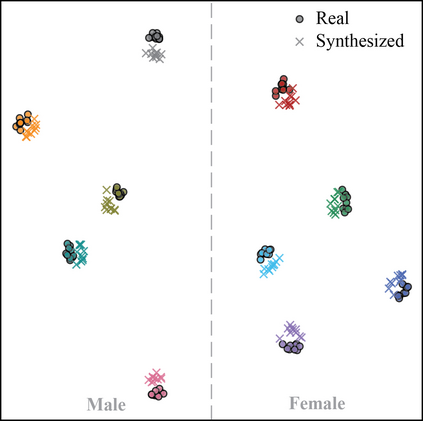
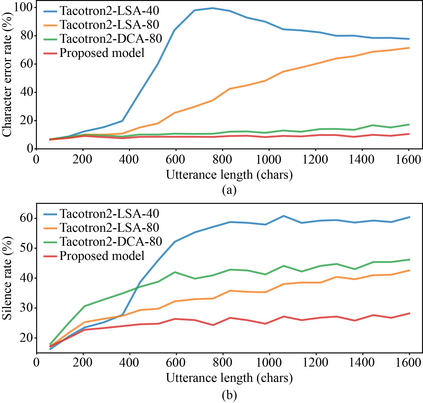
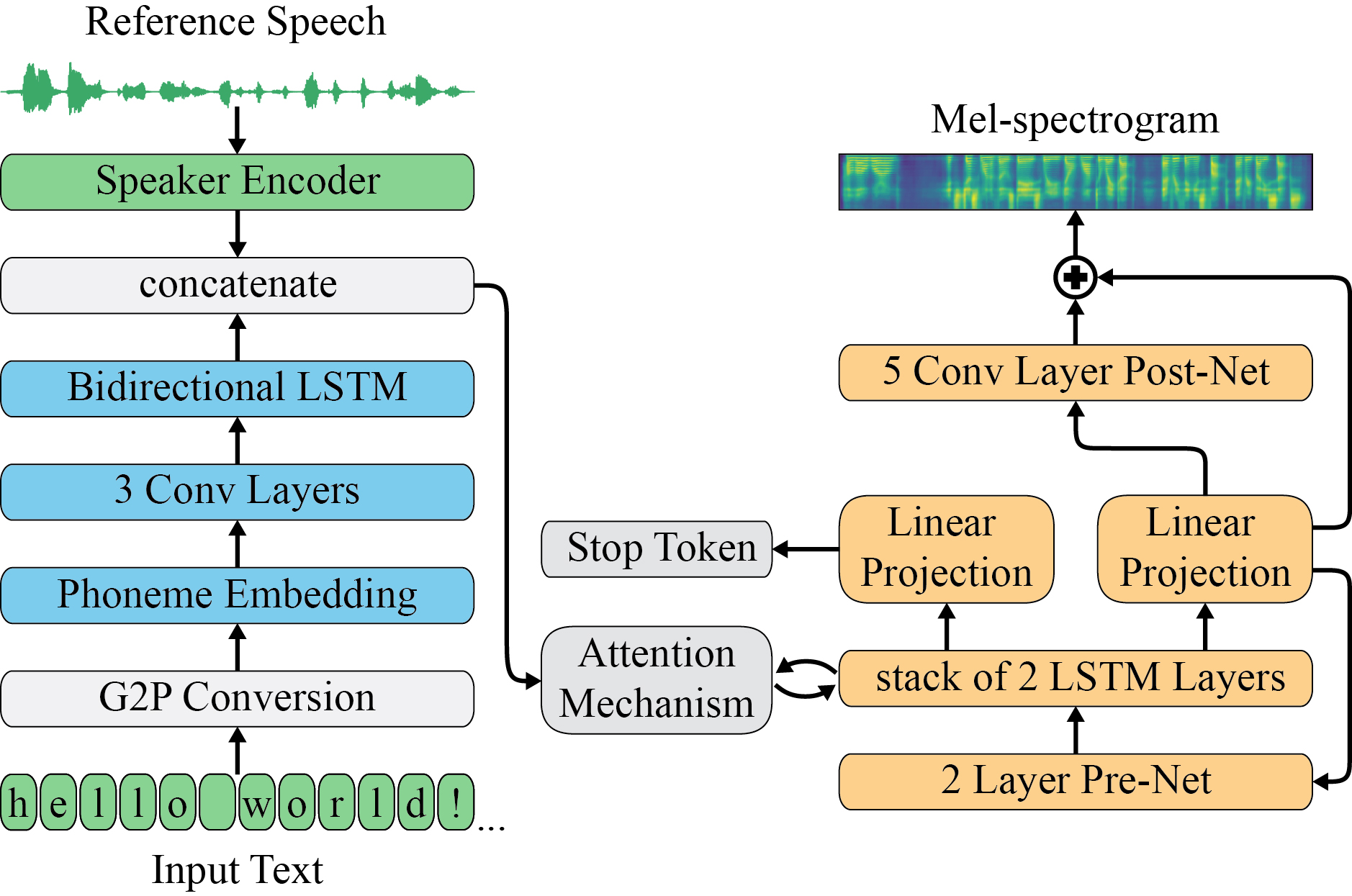
With recent advancements in voice cloning, the performance of speech synthesis for a target speaker has been rendered similar to the human level. However, autoregressive voice cloning systems still suffer from text alignment failures, resulting in an inability to synthesize long sentences. In this work, we propose a variant of attention-based text-to-speech system that can reproduce a target voice from a few seconds of reference speech and generalize to very long utterances as well. The proposed system is based on three independently trained components: a speaker encoder, synthesizer and universal vocoder. Generalization to long utterances is realized using an energy-based attention mechanism known as Dynamic Convolution Attention, in combination with a set of modifications proposed for the synthesizer based on Tacotron 2. Moreover, effective zero-shot speaker adaptation is achieved by conditioning both the synthesizer and vocoder on a speaker encoder that has been pretrained on a large corpus of diverse data. We compare several implementations of voice cloning systems in terms of speech naturalness, speaker similarity, alignment consistency and ability to synthesize long utterances, and conclude that the proposed model can produce intelligible synthetic speech for extremely long utterances, while preserving a high extent of naturalness and similarity for short texts.
翻译:由于最近在语音克隆方面的进步,对目标发言者的语音合成表现与人类水平相似,然而,自动递减式语音克隆系统仍然受到文本调整失败的影响,导致无法合成长句。在这项工作中,我们提议了一种基于注意的文本到语音系统变式系统,这种系统可以从几秒钟的参考演讲中复制一个目标声音,并概括到非常长的发音。拟议的系统基于三个独立培训的组件:一个发言者编译器、合成器和通用电动电解器。通向长语的普及正在使用一种基于能源的注意机制,即动态变动注意,加上基于Tacotron2.的合成器的一套修改建议。此外,有效的零声发言者调整是通过对合成器和语音编码器进行调整来实现的。我们比较了语音克隆系统在语音自然性质、相似性、一致性和合成长话汇能力方面的若干实施情况。我们的结论是,拟议的模型既能保持高清晰的合成语音,又能保持非常长的高度的自然文本。