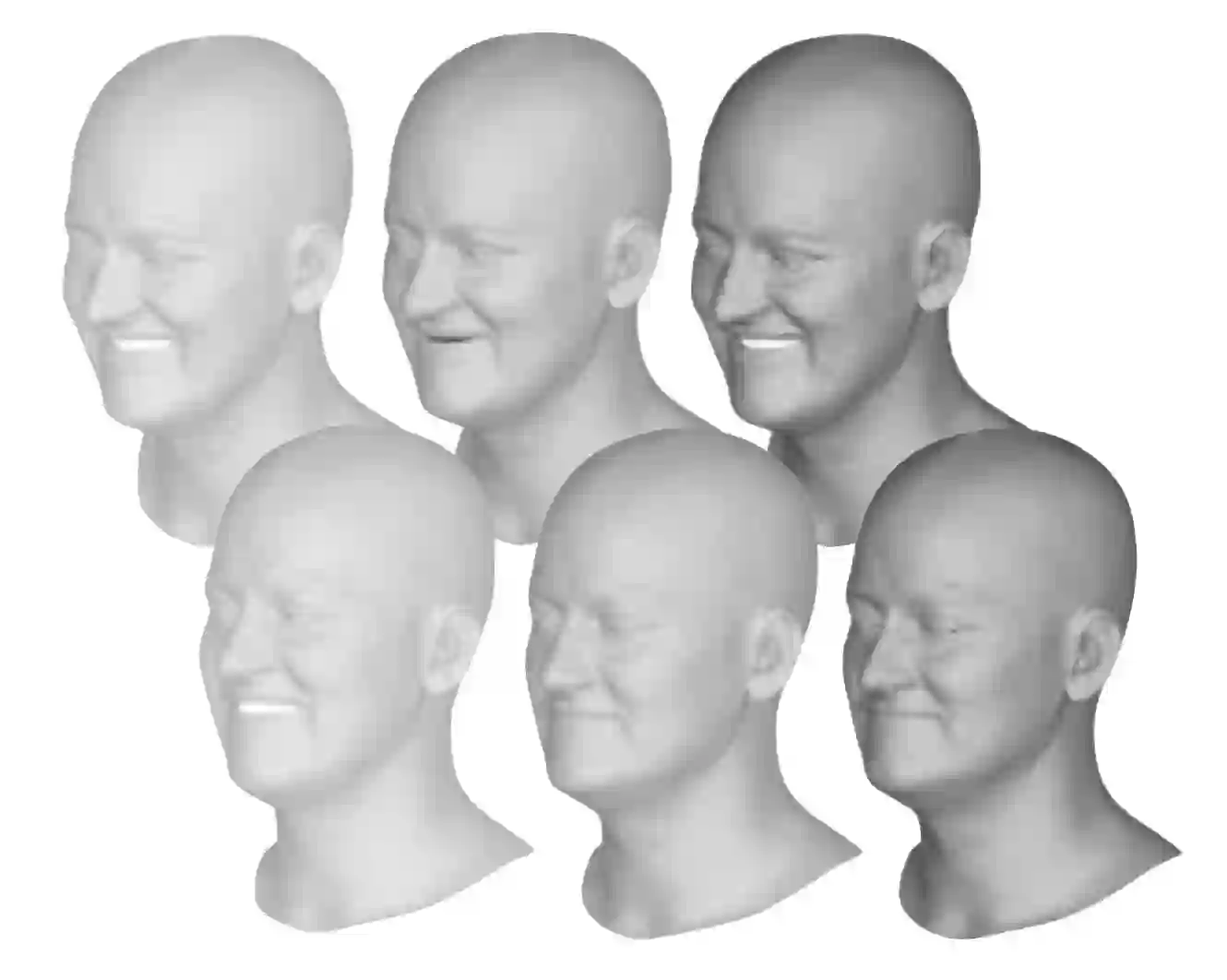
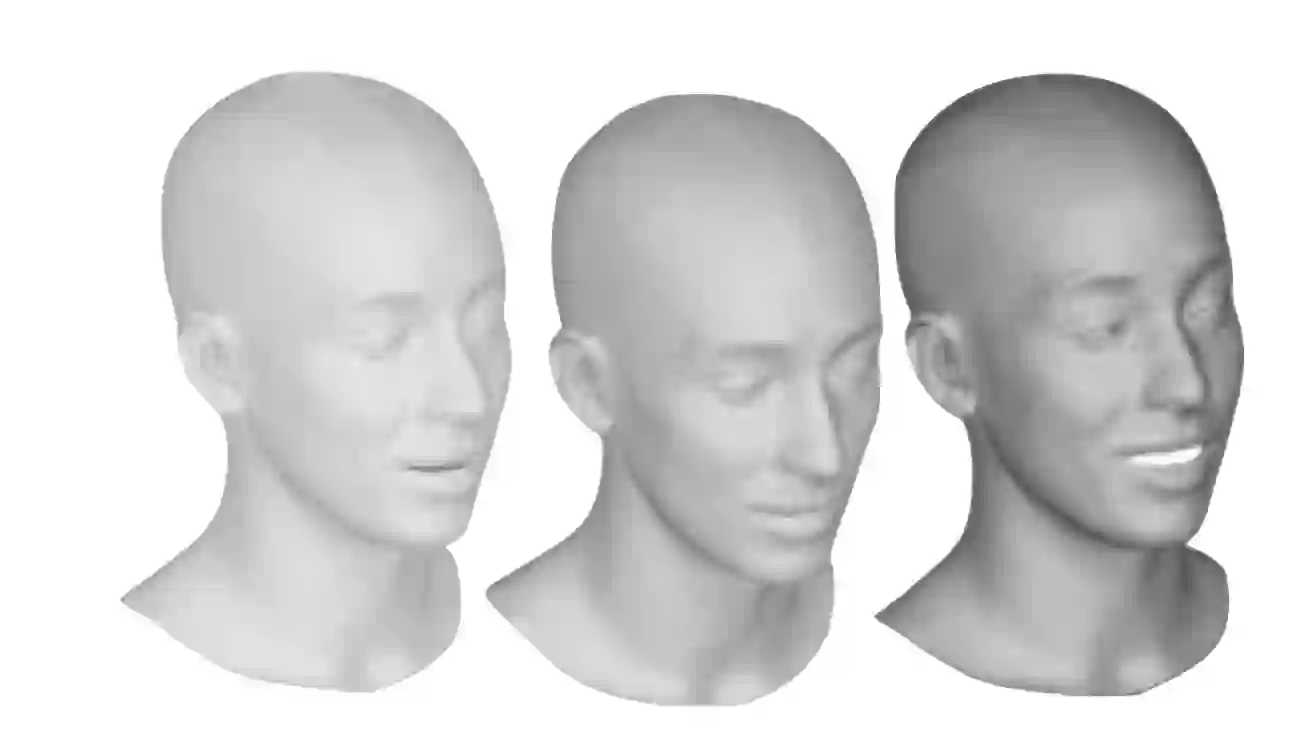
We present a framework for modeling interactional communication in dyadic conversations: given multimodal inputs of a speaker, we autoregressively output multiple possibilities of corresponding listener motion. We combine the motion and speech audio of the speaker using a motion-audio cross attention transformer. Furthermore, we enable non-deterministic prediction by learning a discrete latent representation of realistic listener motion with a novel motion-encoding VQ-VAE. Our method organically captures the multimodal and non-deterministic nature of nonverbal dyadic interactions. Moreover, it produces realistic 3D listener facial motion synchronous with the speaker (see video). We demonstrate that our method outperforms baselines qualitatively and quantitatively via a rich suite of experiments. To facilitate this line of research, we introduce a novel and large in-the-wild dataset of dyadic conversations. Code, data, and videos available at https://evonneng.github.io/learning2listen/.
翻译:我们提出了一个框架,用于模拟dyadi对话中的交互交流:考虑到一名发言者的多式投入,我们自动递减地输出相应的听众运动的多种可能性;我们利用一个运动-Audio交叉关注变压器,将发言者的动作和语音音频结合起来;此外,我们通过学习一种离散的潜在现实的听众运动,以新颖的动作编码VQ-VAE来进行非决定性的预测;我们的方法有机地捕捉了非口头的dyadi互动的多式和非定式性质;此外,它产生了现实的3D听者面部运动,与发言者同步(见视频);我们证明我们的方法在质量和数量上都超过了丰富的一系列实验的基线;为了便利这一研究,我们引入了一种新型的和大型的dyadic对话网上数据集;代码、数据和视频可在https://evonenng.github.io/incledge2listen/上查阅。