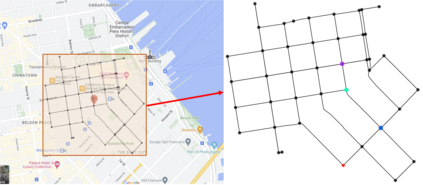
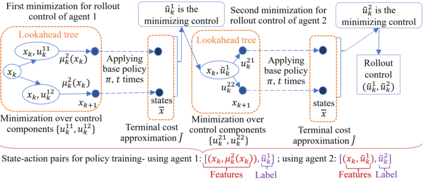
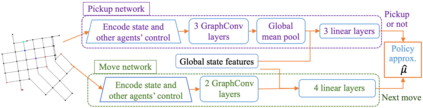
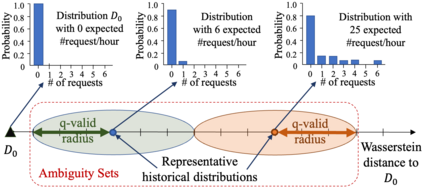
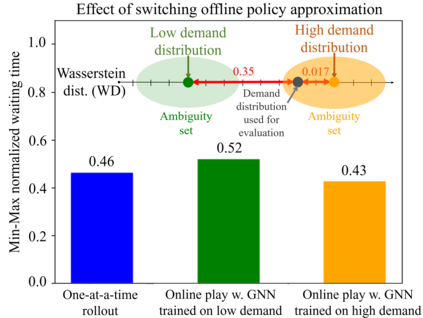
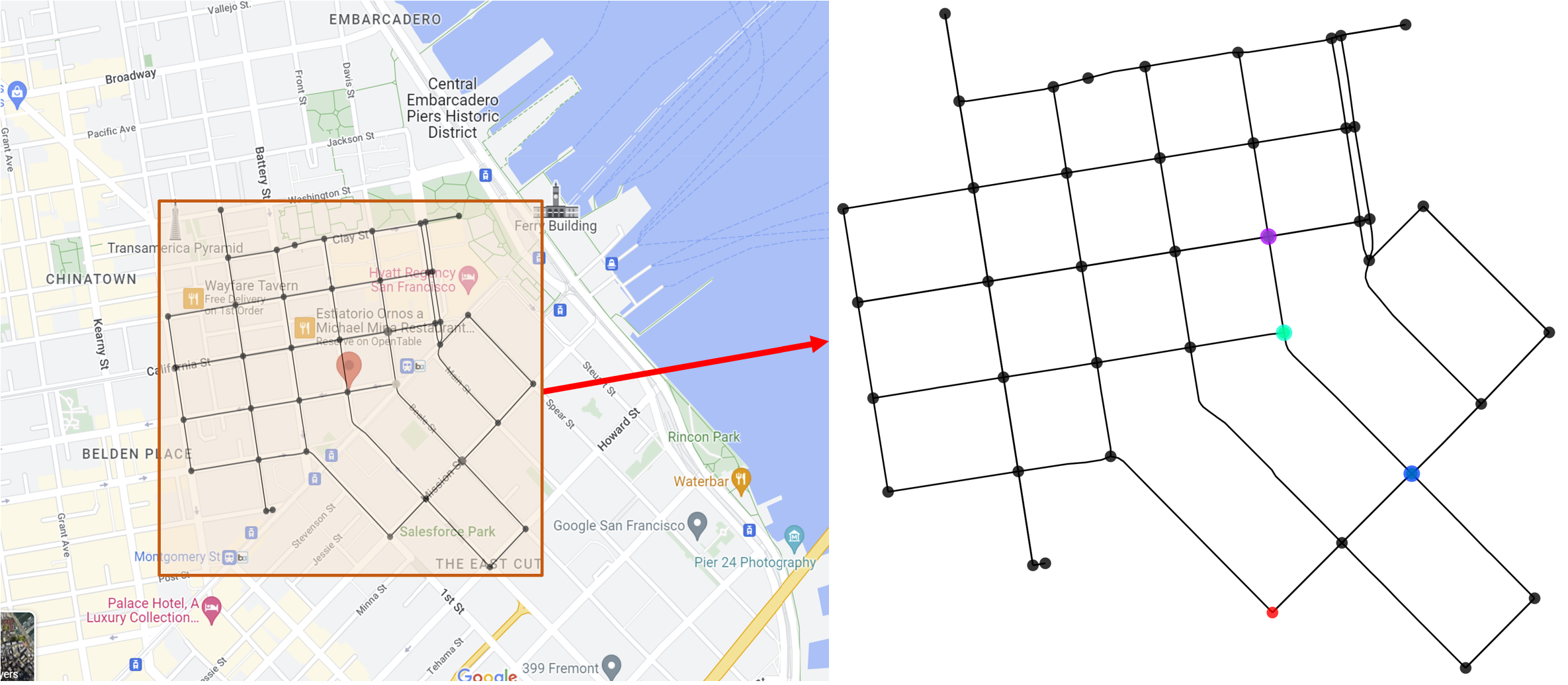
We derive a learning framework to generate routing/pickup policies for a fleet of autonomous vehicles tasked with servicing stochastically appearing requests on a city map. We focus on policies that 1) give rise to coordination amongst the vehicles, thereby reducing wait times for servicing requests, 2) are non-myopic, and consider a-priori potential future requests, 3) can adapt to changes in the underlying demand distribution. Specifically, we are interested in policies that are adaptive to fluctuations of actual demand conditions in urban environments, such as on-peak vs. off-peak hours. We achieve this through a combination of (i) an online play algorithm that improves the performance of an offline-trained policy, and (ii) an offline approximation scheme that allows for adapting to changes in the underlying demand model. In particular, we achieve adaptivity of our learned policy to different demand distributions by quantifying a region of validity using the q-valid radius of a Wasserstein Ambiguity Set. We propose a mechanism for switching the originally trained offline approximation when the current demand is outside the original validity region. In this case, we propose to use an offline architecture, trained on a historical demand model that is closer to the current demand in terms of Wasserstein distance. We learn routing and pickup policies over real taxicab requests in San Francisco with high variability between on-peak and off-peak hours, demonstrating the ability of our method to adapt to real fluctuation in demand distributions. Our numerical results demonstrate that our method outperforms alternative rollout-based reinforcement learning schemes, as well as other classical methods from operations research.
翻译:我们提出了一个学习框架,生成用于城市地图上服务随机出现请求的自主车队的路由/取货策略。我们专注于以下策略:1)引起车辆之间的协调,从而减少等待请求的时间;2)具有非悖论性,考虑先前可能出现的未来请求;3)可以适应基础需求分布的变化。特别是,我们有兴趣的策略是适应城市环境中实际需求情况的波动,例如高峰时段与非高峰时段。我们通过组合以下方式实现了这一点:(i)一种在线游戏算法,以提高离线训练策略的性能,(ii)一种离线近似方案,以适应基础需求模型的变化。特别是,我们通过使用 Wasserstein模糊集的q-有效半径量化有效区域,实现了对我们学习的策略适应不同需求分布的功能。我们提出了一种机制,在当前需求超出原始有效区域时切换最初训练的离线近似。在这种情况下,我们建议使用一个离线体系结构,该离线体系结构是在与当前需求更接近的历史需求模型上进行训练的。我们使用旧金山的实际出租车请求学习路由和取货策略,这些请求在高峰和非高峰时段之间具有高变化性,展示了我们的方法能够适应实际需求分布的波动。我们的数值结果表明,我们的方法优于基于其他滚动强化学习方案以及运筹学中其他古典方法。