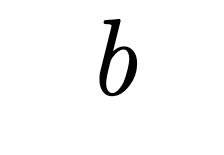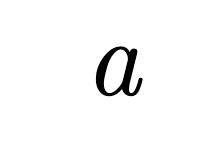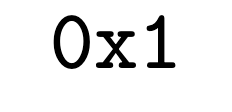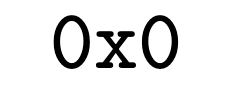The exponential growth of data-intensive machine learning workloads has exposed significant limitations in conventional GPU-accelerated systems, especially when processing datasets exceeding GPU DRAM capacity. We propose MQMS, an augmented in-storage GPU architecture and simulator that is aware of internal SSD states and operations, enabling intelligent scheduling and address allocation to overcome performance bottlenecks caused by CPU-mediated data access patterns. MQMS introduces dynamic address allocation to maximize internal parallelism and fine-grained address mapping to efficiently handle small I/O requests without incurring read-modify-write overheads. Through extensive evaluations on workloads ranging from large language model inference to classical machine learning algorithms, MQMS demonstrates orders-of-magnitude improvements in I/O request throughput, device response time, and simulation end time compared to existing simulators.
翻译:暂无翻译