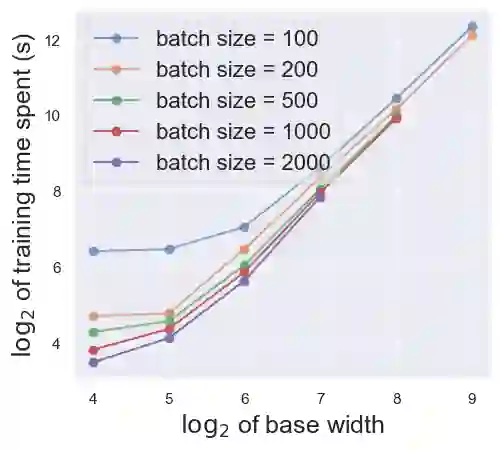
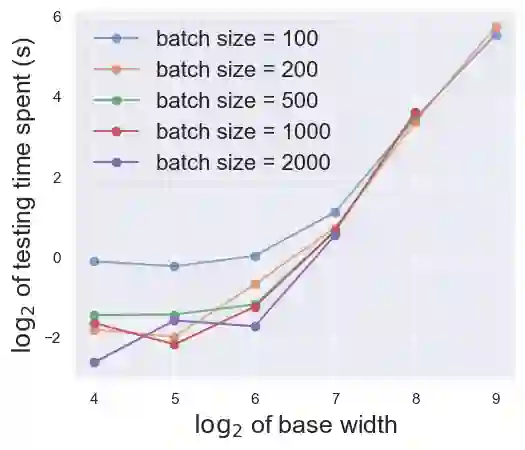
The increasing access to data poses both opportunities and risks in deep learning, as one can manipulate the behaviors of deep learning models with malicious training samples. Such attacks are known as data poisoning. Recent advances in defense strategies against data poisoning have highlighted the effectiveness of aggregation schemes in achieving state-of-the-art results in certified poisoning robustness. However, the practical implications of these approaches remain unclear. Here we focus on Deep Partition Aggregation, a representative aggregation defense, and assess its practical aspects, including efficiency, performance, and robustness. For evaluations, we use ImageNet resized to a resolution of 64 by 64 to enable evaluations at a larger scale than previous ones. Firstly, we demonstrate a simple yet practical approach to scaling base models, which improves the efficiency of training and inference for aggregation defenses. Secondly, we provide empirical evidence supporting the data-to-complexity ratio, i.e. the ratio between the data set size and sample complexity, as a practical estimation of the maximum number of base models that can be deployed while preserving accuracy. Last but not least, we point out how aggregation defenses boost poisoning robustness empirically through the poisoning overfitting phenomenon, which is the key underlying mechanism for the empirical poisoning robustness of aggregations. Overall, our findings provide valuable insights for practical implementations of aggregation defenses to mitigate the threat of data poisoning.
翻译:暂无翻译