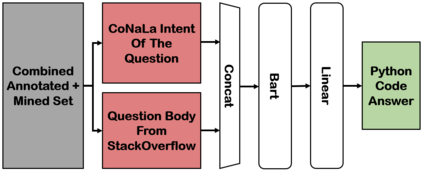
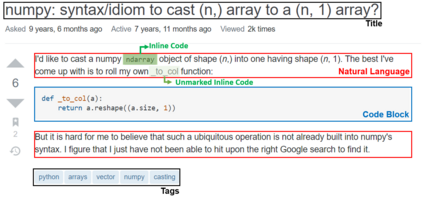
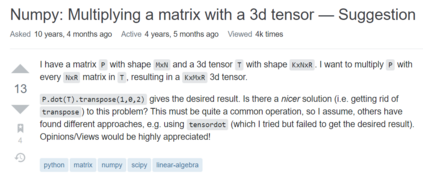
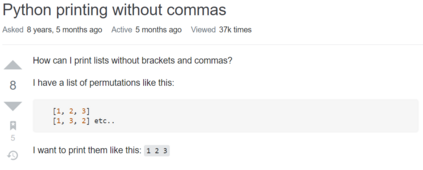
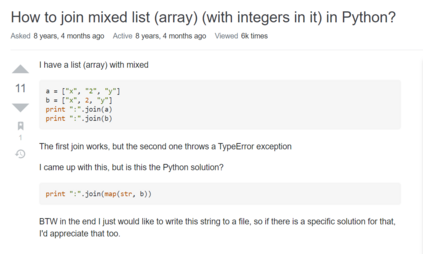
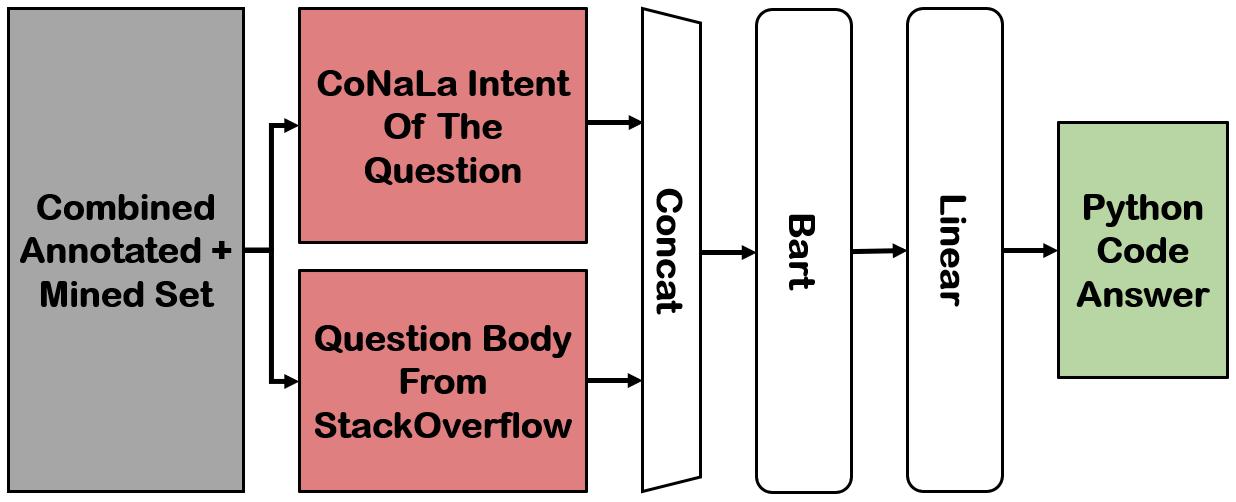
Answering a programming question using only its title is difficult as salient contextual information is omitted. Based on this observation, we present a corpus of over 40,000 StackOverflow question texts to be used in conjunction with their corresponding intents from the CoNaLa dataset (Yin et al., 2018). Using both the intent and question body, we use BART to establish a baseline BLEU score of 34.35 for this new task. We find further improvements of $2.8\%$ by combining the mined CoNaLa data with the labeled data to achieve a 35.32 BLEU score. We evaluate prior state-of-the-art CoNaLa models with this additional data and find that our proposed method of using the body and mined data beats the BLEU score of the prior state-of-the-art by $71.96\%$. Finally, we perform ablations to demonstrate that BART is an unsupervised multimodal learner and examine its extractive behavior. The code and data can be found https://github.com/gabeorlanski/stackoverflow-encourages-cheating.
翻译:仅使用标题的编程问题很难解答,因为没有明显的背景资料。根据这项观察,我们提供了40,000多份StackOverproll问题文本,与CoNaLa数据集的相应意图一起使用(Yin等人,2018年)。我们利用意图和问题体,利用BART为这项新任务确定基线BLEU分数34.35。我们发现,通过将已开采的CoNaLa数据与标签数据合并,实现35.32 BLEU分,进一步改进了2.8美元。我们用这一额外数据评估了以前最先进的CoNaLa模型,发现我们拟议的使用尸体和所探测数据的方法比BLEU前的分数高出71.96美元。最后,我们做了一些推理,以证明BART是一个不受监督的多式联运学习者,并检查其采掘行为。代码和数据可以找到 https://github.com/gaberlanski/stackoverflow-encourages-chestating。