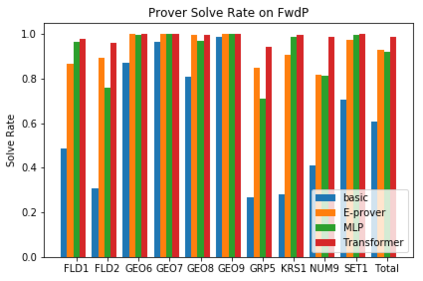
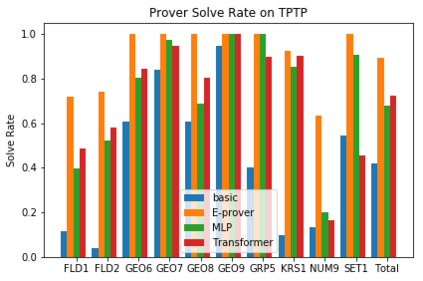
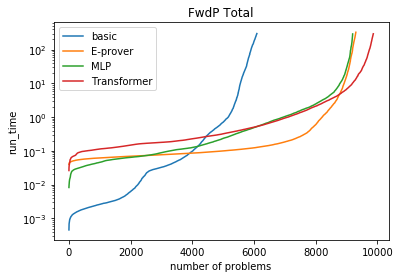
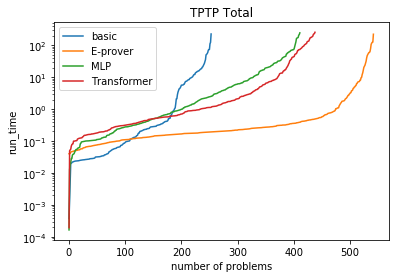
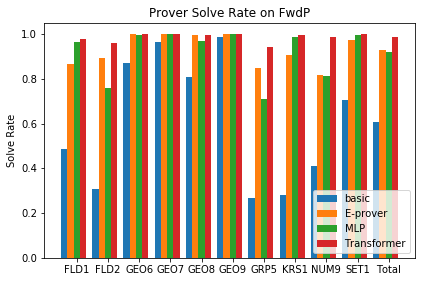
A major challenge in applying machine learning to automated theorem proving is the scarcity of training data, which is a key ingredient in training successful deep learning models. To tackle this problem, we propose an approach that relies on training purely with synthetically generated theorems, without any human data aside from axioms. We use these theorems to train a neurally-guided saturation-based prover. Our neural prover outperforms the state-of-the-art E-prover on this synthetic data in both time and search steps, and shows significant transfer to the unseen human-written theorems from the TPTP library, where it solves 72\% of first-order problems without equality.
翻译:应用机器学习自动理论验证的一个主要挑战是缺乏培训数据,而培训数据是培训成功深层学习模式的一个关键要素。为了解决这一问题,我们建议采用一种完全依靠人工生成的理论培训的方法,除了轴心外,没有人类数据。我们用这些理论来培训以神经导导向饱和为基础的验证。我们的神经验证在时间和搜索步骤上都优于关于这一合成数据的最新电子预测,并显示从TPTP图书馆向看不见的人类书写理论的重大转移,在那里,它无平等地解决了72-Q的一级问题。