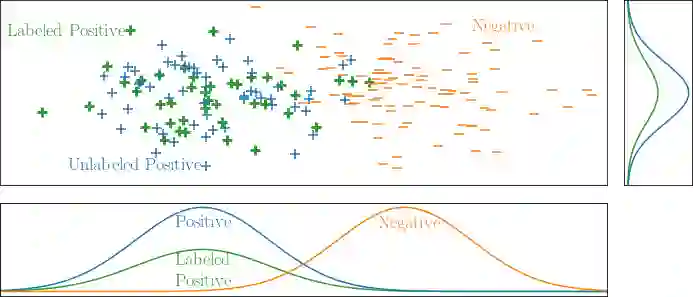
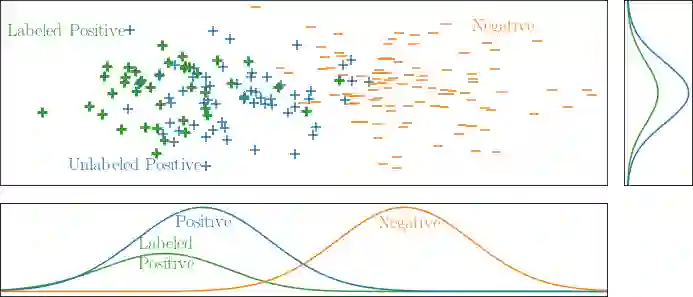
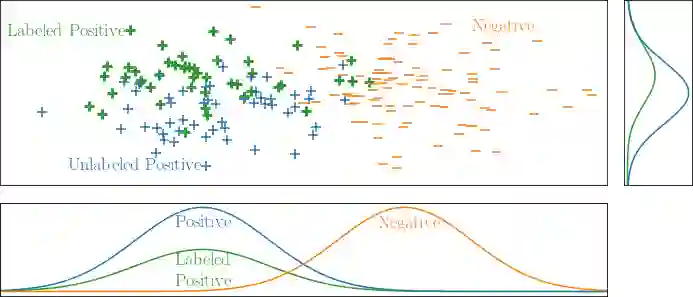
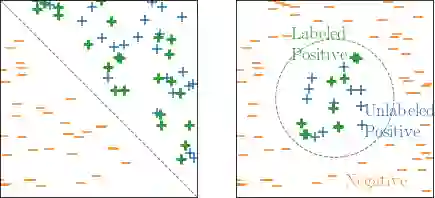
Learning from positive and unlabeled data or PU learning is the setting where a learner only has access to positive examples and unlabeled data. The assumption is that the unlabeled data can contain both positive and negative examples. This setting has attracted increasing interest within the machine learning literature as this type of data naturally arises in applications such as medical diagnosis and knowledge base completion. This article provides a survey of the current state of the art in PU learning. It proposes seven key research questions that commonly arise in this field and provides a broad overview of how the field has tried to address them.
翻译:从正面和未贴标签的数据或 PU 学习中学习是学习者只能获得正面实例和未贴标签数据的环境,其假设是,未贴标签的数据可以包含正面和负面的例子,这种环境在机器学习文献中引起了越来越多的兴趣,因为这种类型的数据自然产生于医学诊断和知识库完成等应用中,本文章对PU 学习中最新艺术状况进行了调查,提出了该领域常见的七个关键研究问题,并广泛概述了实地如何努力解决这些问题。