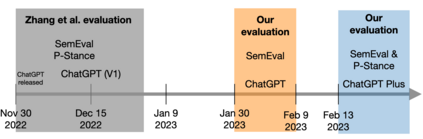
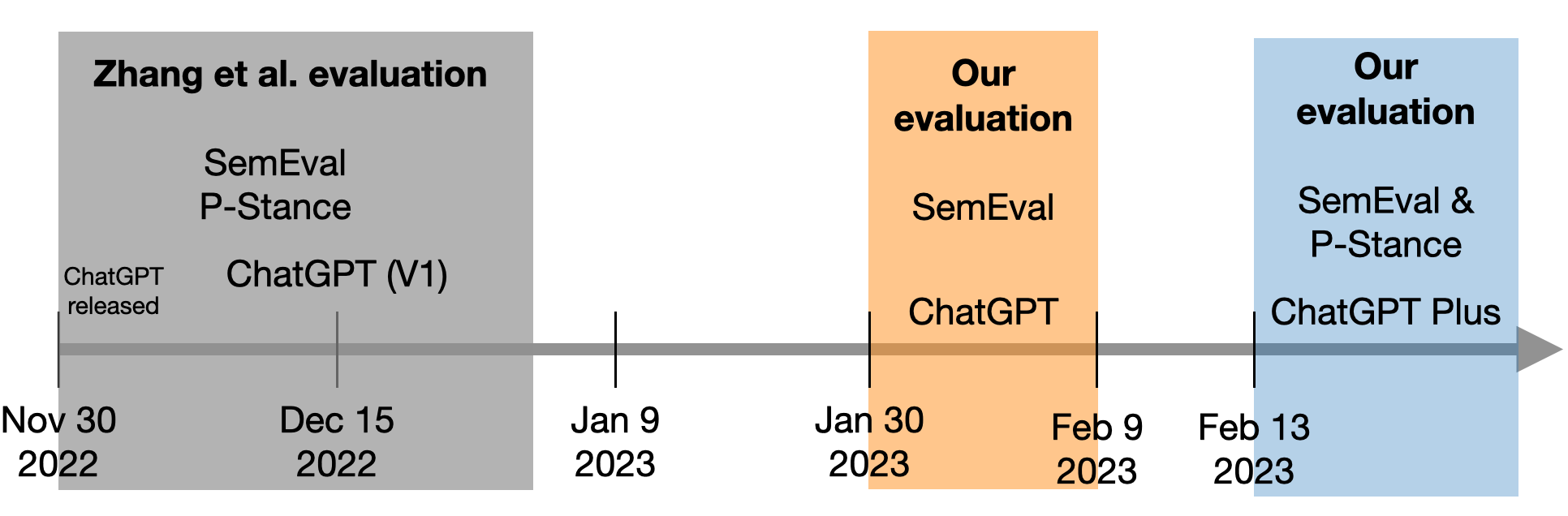
ChatGPT, the first large language model (LLM) with mass adoption, has demonstrated remarkable performance in numerous natural language tasks. Despite its evident usefulness, evaluating ChatGPT's performance in diverse problem domains remains challenging due to the closed nature of the model and its continuous updates via Reinforcement Learning from Human Feedback (RLHF). We highlight the issue of data contamination in ChatGPT evaluations, with a case study of the task of stance detection. We discuss the challenge of preventing data contamination and ensuring fair model evaluation in the age of closed and continuously trained models.
翻译:ChatGPT是第一个被广泛采用的大型语言模型,已在许多自然语言任务中展现出了卓越的性能。尽管它的显着实用性,由于模型的封闭性和通过人类反馈不断更新的求解增强学习(RLHF)算法,评估ChatGPT在多样化问题领域的性能仍然具有挑战性。我们重点针对ChatGPT评估中的数据污染问题进行案例研究,以stance detection任务为例。我们讨论了在封闭和不断训练模型时如何防止数据污染并确保公正的模型评估的挑战。