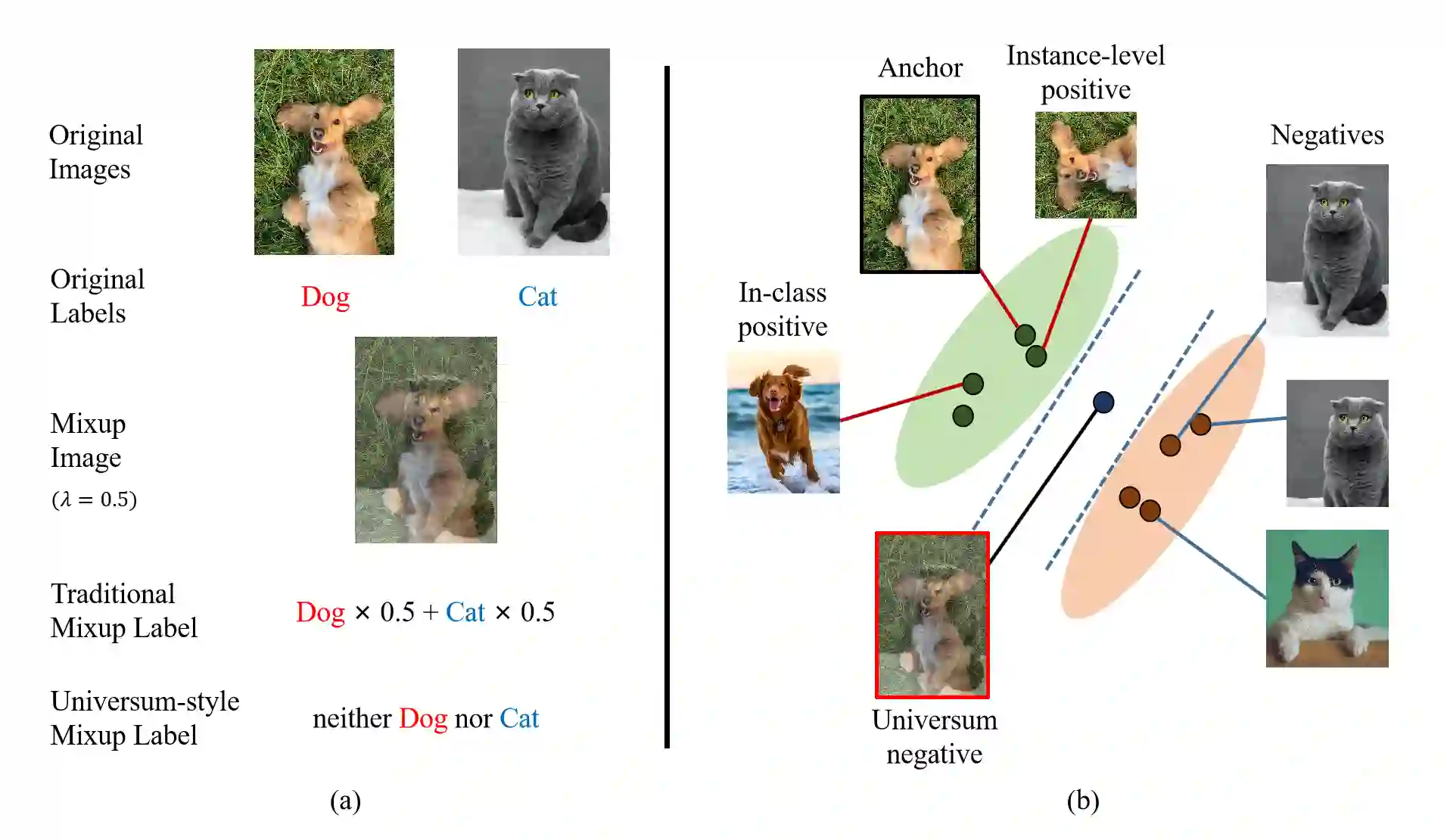
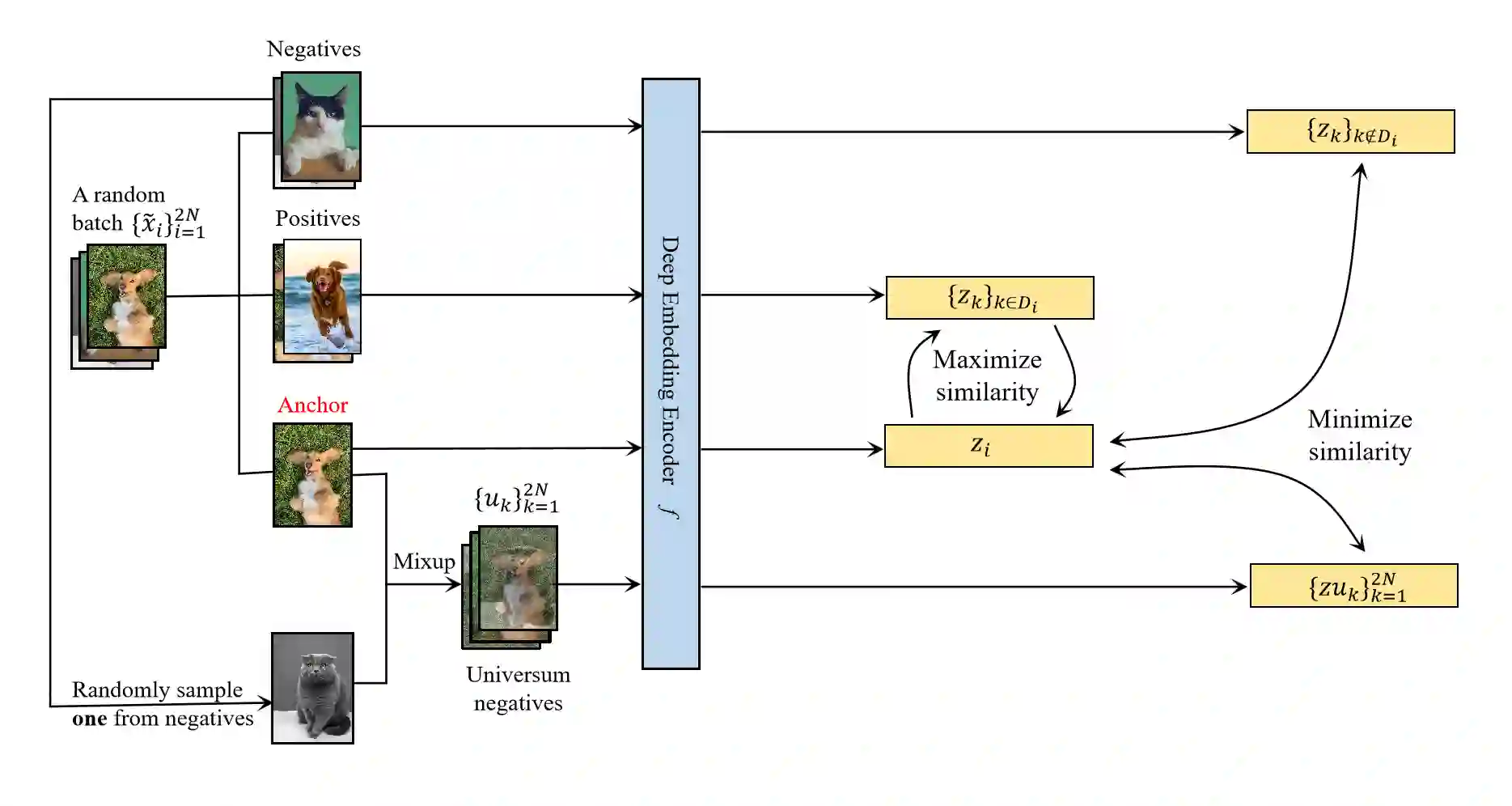
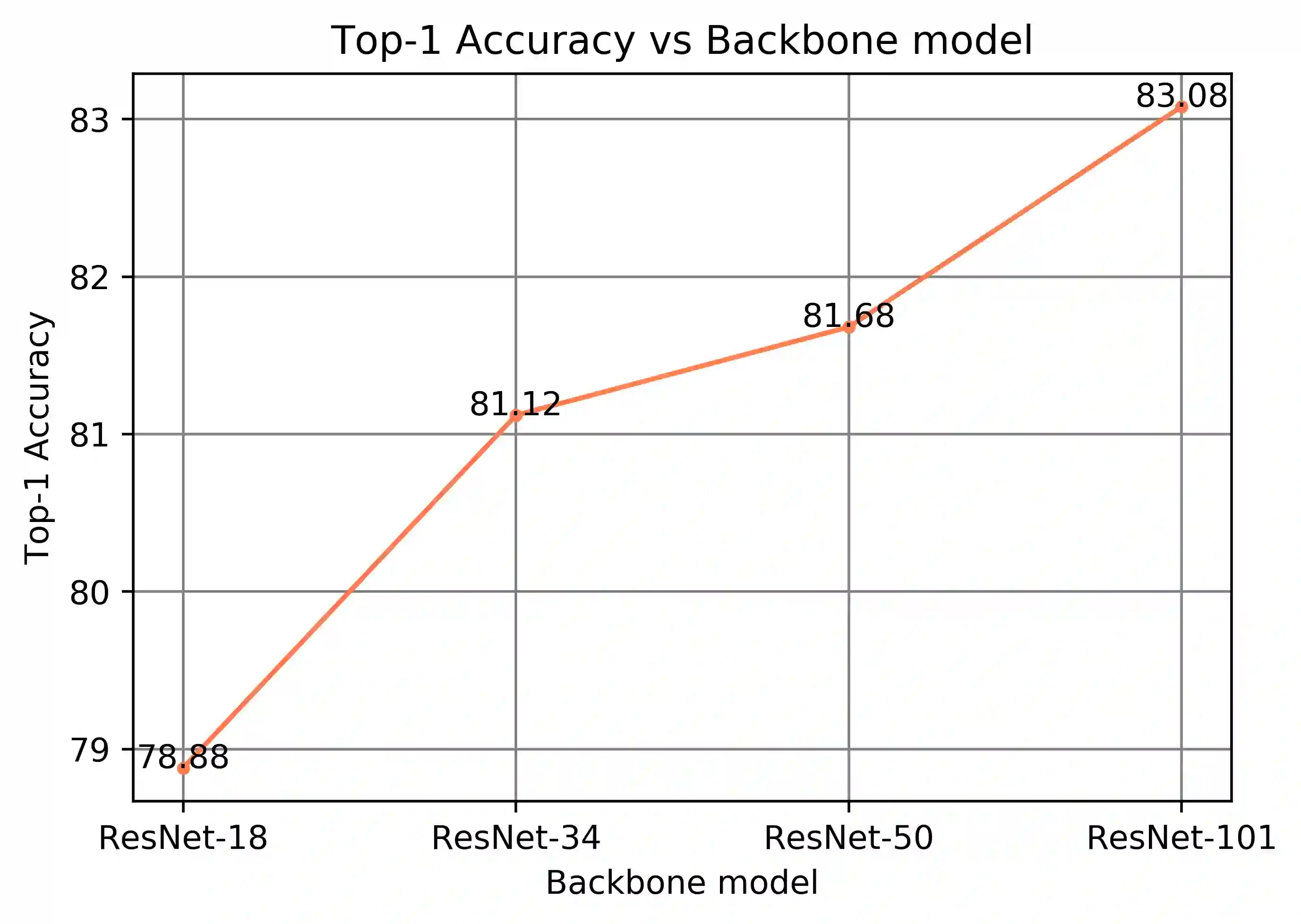
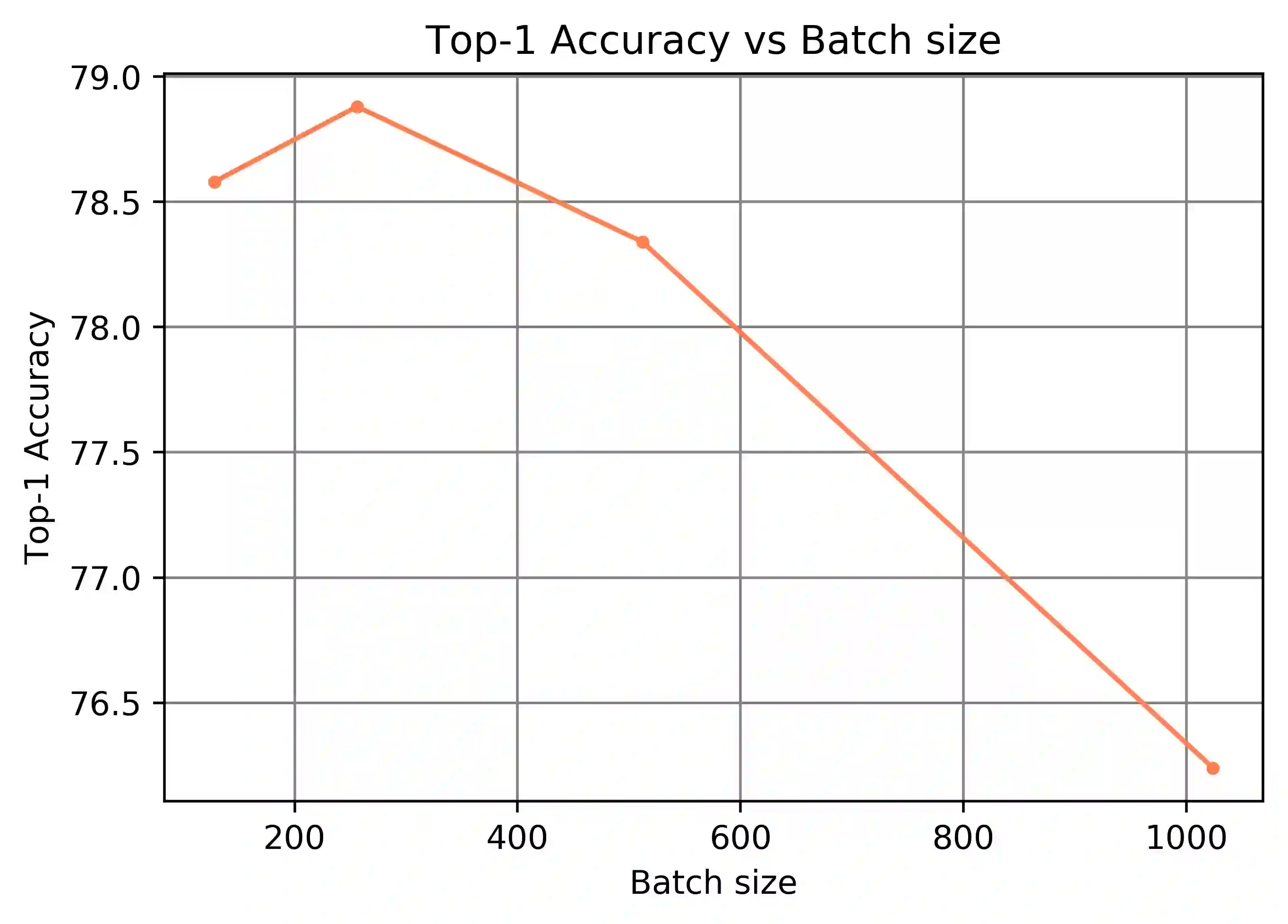
Mixup is an efficient data augmentation method which generates additional samples through respective convex combinations of original data points and labels. Although being theoretically dependent on data properties, Mixup is reported to perform well as a regularizer and calibrator contributing reliable robustness and generalization to neural network training. In this paper, inspired by Universum Learning which uses out-of-class samples to assist the target tasks, we investigate Mixup from a largely under-explored perspective - the potential to generate in-domain samples that belong to none of the target classes, that is, universum. We find that in the framework of supervised contrastive learning, universum-style Mixup produces surprisingly high-quality hard negatives, greatly relieving the need for a large batch size in contrastive learning. With these findings, we propose Universum-inspired Contrastive learning (UniCon), which incorporates Mixup strategy to generate universum data as g-negatives and pushes them apart from anchor samples of the target classes. Our approach not only improves Mixup with hard labels, but also innovates a novel measure to generate universum data. With a linear classifier on the learned representations, our method achieves 81.68% top-1 accuracy on CIFAR-100, surpassing the state of art by a significant margin of 5% with a much smaller batch size, typically, 256 in UniCon vs. 1024 in SupCon using ResNet-50.
翻译:混合是一种高效的数据增强方法,它通过原始数据点和标签的混凝土组合产生更多的样本。 虽然在理论上取决于数据属性, 但据报告,混集是正常和校准的,为神经网络培训提供了可靠的稳健性和概括性。 在本文中,由大学学习的启发,它利用类外样本协助目标任务。 我们从大部分探索不足的角度来调查混集—— 生成不属于目标类别的任何类( universum) 的内部样本的可能性。 我们发现,在受监督的对比学习框架内, 单向式混集型混合能够产生出奇高质量的硬性负值, 大大缓解了对神经网络培训进行大规模批量学习的需要。 根据这些发现, 我们提议由Universum激发的对比性学习( Unicicontroducation) (Unitical) 战略可以生成单向组合数据, 并且将数据推向目标类中固定的样本。 我们的方法不仅仅是用硬性标签和单向50型混成的硬性硬性硬性硬性缩缩缩缩缩缩缩缩缩缩缩缩缩缩缩缩缩缩图。