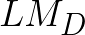Causal Video Question Answering (CVidQA) queries not only association or temporal relations but also causal relations in a video. Existing question synthesis methods pre-trained question generation (QG) systems on reading comprehension datasets with text descriptions as inputs. However, QG models only learn to ask association questions (e.g., ``what is someone doing...'') and result in inferior performance due to the poor transfer of association knowledge to CVidQA, which focuses on causal questions like ``why is someone doing ...''. Observing this, we proposed to exploit causal knowledge to generate question-answer pairs, and proposed a novel framework, Causal Knowledge Extraction from Language Models (CaKE-LM), leveraging causal commonsense knowledge from language models to tackle CVidQA. To extract knowledge from LMs, CaKE-LM generates causal questions containing two events with one triggering another (e.g., ``score a goal'' triggers ``soccer player kicking ball'') by prompting LM with the action (soccer player kicking ball) to retrieve the intention (to score a goal). CaKE-LM significantly outperforms conventional methods by 4% to 6% of zero-shot CVidQA accuracy on NExT-QA and Causal-VidQA datasets. We also conduct comprehensive analyses and provide key findings for future research.
翻译:因果视频问答(CVidQA)不仅查询关联或时间关系,还查询视频中的因果关系。现有的问题合成方法在阅读理解数据集上预训练问题生成(QG)系统,输入为文本描述。然而,QG模型只学习提问关联问题(例如,“某人在做什么...”),导致由于关联知识向CVidQA的转移差,表现较差。观察到这一点,我们提出利用因果知识生成问题-答案对,并提出了一个新颖的框架——从语言模型中提取因果知识(CaKE-LM),利用语言模型的因果常识知识来解决CVidQA。为了从语言模型中提取知识,CaKE-LM通过使用行为(足球运动员踢球)提示LM以检索意图(进球)来生成包含两个事件的因果问题(例如,“进球”触发“足球运动员踢球”)。CaKE-LM在NExT-QA和Causal-VidQA数据集上的零样本CVidQA准确率比传统方法高4%至6%。我们还进行了综合分析并提供了未来研究的关键发现。