

开放知识图谱(KG)补全的任务是从已知事实中提取新的发现。现有的增强KG补全的工作需要:(1)事实三元组来扩大图推理空间,或者(2)手动设计提示来从预训练的语言模型(PLM)中提取知识,这种方式的性能有限,需要专家付出昂贵的努力。为此,我们提出了TAGREAL,它可以自动生成高质量的查询提示,并从大型文本语料库中检索支持信息,以探测PLM中的知识进行KG补全。结果显示,TAGREAL在两个基准数据集上实现了最新的性能。我们发现,即使在训练数据有限的情况下,TAGREAL的性能也非常出色,超过了现有的基于嵌入的、基于图的和基于PLM的方法。
1. 引言
知识图谱(KG)是一种异构图,它以实体-关系-实体三元组的形式编码事实信息,其中关系连接头实体和尾实体(例如,“迈阿密位于-美国”)(Wang et al., 2017;Hogan et al., 2021)。KG(Dai et al., 2020)在许多NLP应用中起着核心作用,包括问答系统(Hao et al., 2017;Yasunaga et al., 2021)、推荐系统(Zhou et al., 2020)和药物发现(Zitnik et al., 2018)。然而,现有的研究(Wang et al., 2018;Hamilton et al., 2018)显示,大部分大规模KG都是不完整的,无法全面覆盖庞大的现实世界知识。这个挑战促使了KG补全,其目标是给定主题实体和关系,找出一个或多个对象实体(Lin et al., 2015)。例如,在图1中,我们的目标是预测对象实体,其中“底特律”是主题实体,“包含于”是关系。

然而,现有的KG补全方法(Trouillon et al., 2016b;Das et al., 2018)存在几个限制(Fu et al., 2019)。首先,他们的性能严重依赖于图的密度。他们通常在具有丰富结构信息的密集图上表现良好,但在更常见的稀疏图上表现不佳。其次,以前的方法(例如,Bordes et al.(2013))假设一个封闭世界的KG,没有考虑外部资源中的大量开放知识。实际上,在许多情况下,KG通常与丰富的文本语料库(Bodenreider, 2004)相关联,其中包含大量尚未提取的事实数据。为了克服这些挑战,我们研究了开放知识图谱补全的任务,其中KG可以使用来自KG外部的新事实进行构建。最近的文本富集解决方案(Fu et al., 2019)关注使用预定义的事实集来丰富知识图谱。然而,预定义的事实集通常嘈杂且受限,也就是说,它们没有提供足够的信息来有效更新KG。
预训练语言模型(PLMs)(Devlin et al., 2019; Liu et al., 2019a)已被证明在隐式从大量未标记文本中学习 factual knowledge 上非常强大(Petroni et al., 2019b)。由于 PLMs 在文本编码方面非常出色,它们可以被用来利用外部文本信息帮助知识图谱补全。最近的知识图谱补全方法(Shin et al., 2020; Lv et al., 2022)侧重于使用手工制作的提示(例如,在图1中的“底特律位于[MASK]”)来查询 PLMs 进行图谱补全(例如,“密歇根州”)。然而,手动创建提示可能代价昂贵且质量有限(例如,对于手工制作的提示的查询,PLM给出了错误的答案“加拿大”,如图1所示)。
预训练语言模型(PLMs)(Devlin et al., 2019; Liu et al., 2019a)已被证明在隐式从大量未标记文本中学习 factual knowledge 上非常强大(Petroni et al., 2019b)。由于 PLMs 在文本编码方面非常出色,它们可以被用来利用外部文本信息帮助知识图谱补全。最近的知识图谱补全方法(Shin et al., 2020; Lv et al., 2022)侧重于使用手工制作的提示(例如,在图1中的“底特律位于[MASK]”)来查询 PLMs 进行图谱补全(例如,“密歇根州”)。然而,手动创建提示可能代价昂贵且质量有限(例如,对于手工制作的提示的查询,PLM给出了错误的答案“加拿大”,如图1所示)。
基于标准KG的上述限制和PLMs(Devlin et al., 2019;Liu et al., 2019a)的巨大能力,我们的目标是使用PLMs进行开放知识图谱补全。我们提出了一个端到端的框架,共同利用PLMs中的隐含知识和语料库中的文本信息来进行知识图谱补全(如图1所示)。与现有的工作不同(例如,(Fu et al., 2019;Lv et al., 2022)),我们的方法不需要手动预定义的事实和提示集,这使得它更具通用性,更易于适应实际应用。我们的贡献可以总结为:
• 我们研究了可以通过从PLMs中捕捉到的事实进行辅助的开放KG补全问题。为此,我们提出了一个新的框架TAGREAL,它表示了用PLMs中的现实世界知识增强的开放KG补全。 • 我们开发了提示生成和信息检索方法,这使得TAGREAL能够自动创建高质量的PLM知识探测提示,并搜索支持信息,特别是当PLMs缺乏某些领域知识时,这使得它更加实用。 • 通过在Freebase等实际知识图谱上的大量定量和定性实验,我们展示了我们框架的适用性和优点。 2. 方法
我们提出了TAGREAL,一个基于PLM的框架来处理KG补全任务。与以前的工作相比,我们的框架不依赖手工制作的提示或预定义的相关事实。如图2所示,我们自动创建合适的提示并搜索相关的支持信息,这些信息进一步被用作模板,以从PLMs中探索隐含的知识。
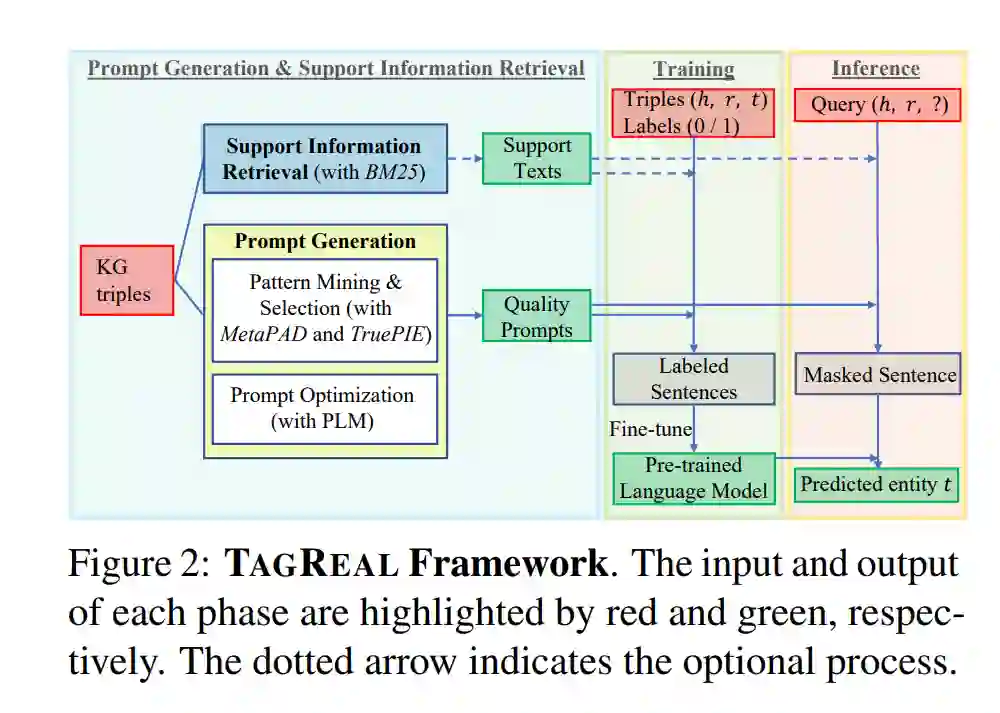
2.1 问题定义
知识图谱补全的目的是在KG的现有三元组集合中添加新的三元组(事实)。为了实现这个目标,有两个任务。第一个是三元组分类,这是一个二元分类任务,用于预测一个三元组(h, r, t)是否属于KG,其中h, r, t分别表示头实体、关系和尾实体。第二个任务是链接预测,其目标是预测查询(h, r, ?)的尾实体t或者预测查询(?, r, t)的头实体h。
2.2 提示生成 Prompt Generation
之前的研究(例如,Jiang等人(2020))表明,从预训练语言模型(PLMs)中提取关系知识的准确性,很大程度上依赖于用于查询的提示的质量。为了达到这个目的,我们开发了一种全面的方法,只需要将知识图谱中的三元组作为输入,就可以自动生成高质量的提示,如图3所示。我们使用文本模式挖掘方法从大型语料库中挖掘出高质量的模式,作为用于从PLMs中探索知识的提示。据我们所知,我们是首次使用文本模式挖掘方法进行语言模型提示挖掘的研究者。我们认为这种方法具有以下应用性:
• 数据源相似。我们在大型语料库(例如,维基百科)上应用模式挖掘,这些语料库是大多数PLMs预训练的数据源。 •** 目标相似**。文本模式挖掘的目的是从大型语料库中挖掘出模式以提取新信息;提示挖掘的目的是挖掘出提示以从PLMs中探测隐含的知识。 • 性能标准相似。模式或提示的可靠性取决于它能从语料库/PLMs中提取出多少准确的事实。
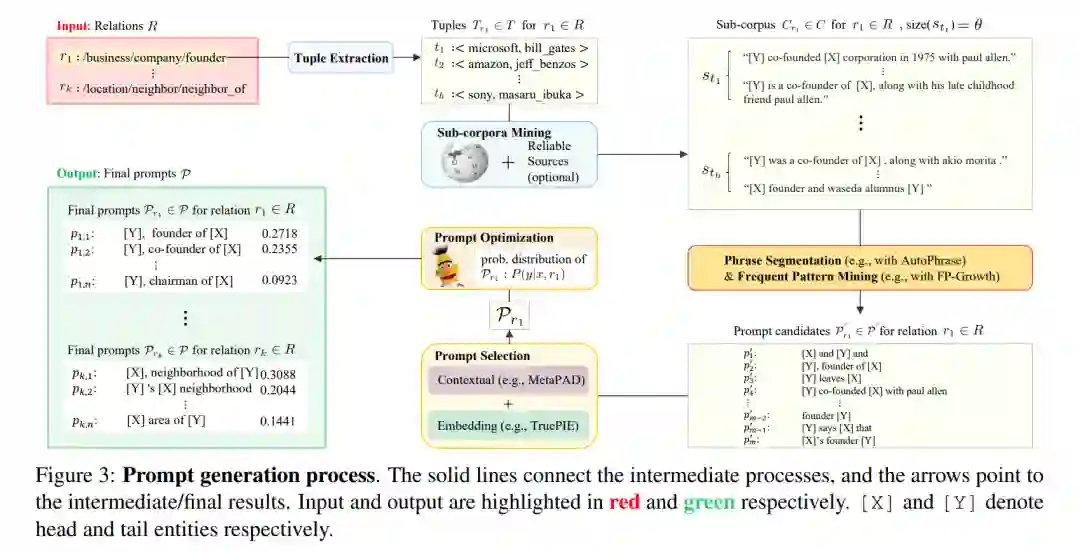
2.3 支持信息检索 Support Information Retrieval
除了提示挖掘外,我们还将一些查询相关和三元组相关的支持文本信息附加到提示中,以帮助PLMs理解我们想要探测的知识,以及帮助训练三元组分类能力。如图4所示,对于关系r中的第i个查询q r i,我们使用BM25(Robertson等人,1995)从可靠的语料库中检索得分高于δ且长度小于ϕ的高排名支持文本,并随机选择其中一个作为支持信息。为了组成输入到PLM的填空qˆ r i,我们将支持文本连接到我们在前面步骤中通过优化得到的每个提示中,其中主体已填充,对象被掩盖。[CLS]和[SEP]分别是用于序列分类和支持信息-提示分隔的标记。在训练阶段,我们使用三元组而不是查询来搜索文本,而[MASK]将被对象实体填充。值得注意的是,支持文本在TAGREAL中是可选的,如果没有找到匹配的数据,我们将其留空。
**2.4 训练 **
为了训练我们的模型,我们根据PKGC(Lv等人,2022)提出的思想,除了给定的正三元组外,我们还创建负三元组,以处理三元组分类任务。我们通过将每个正三元组中的头部和尾部替换为KGE模型给出高概率的“错误”实体,来创建负三元组。我们还通过随机替换头部和尾部,创建随机负样本,以扩大负训练/验证三元组的集合。
**2.5 推理 **
给定一个查询 (h, r, ?),我们应用与头实体 h 和关系 r 相关的查询相关的支持信息,因为我们假设我们不知道尾实体(我们的预测目标)。然后,我们制作包含 [MASK] 的相应查询实例,既包含支持信息也包含提示集合,如图4所示。为了在链接预测中利用 PLM 的三元组分类能力,我们用已知实体集中的每个实体替换查询实例中的 [MASK],并按降序排列它们的分类分数,以创建一个一维向量,作为每个查询的预测结果。这表明,向量中索引较低的实体更有可能与输入查询组成正三元组。对于提示集合,我们在排序之前按实体索引将分数相加。详细的说明放在附录E中。
3. 实验
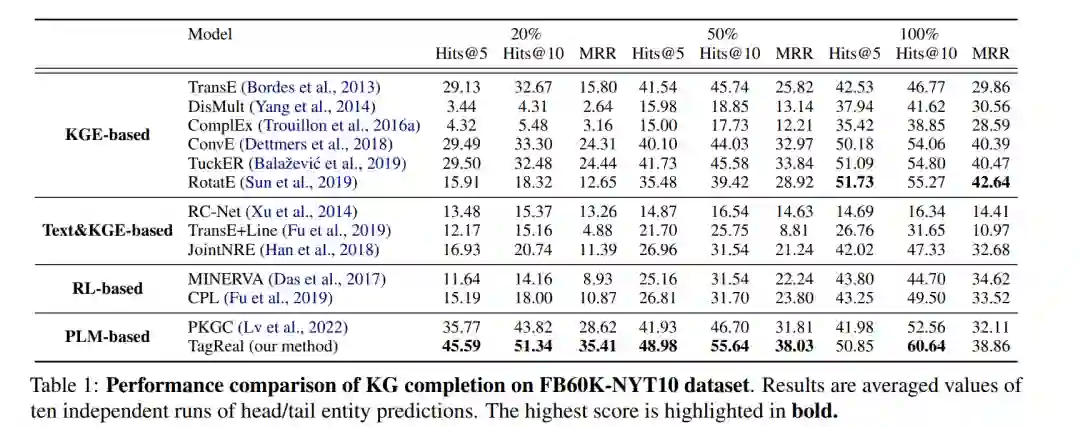
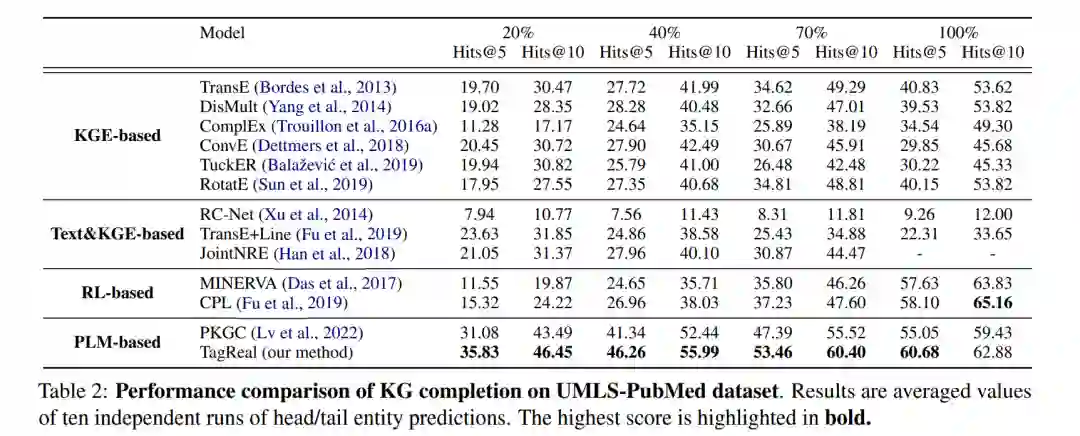
我们将我们的模型 TAGREAL 与四种方法进行比较。对于(1)传统的知识图谱嵌入方法,我们评估了 TransE (Bordes 等人,2013),DisMult (Yang 等人,2014),ComplEx (Trouillon 等人,2016a),ConvE (Dettmers 等人,2018),TuckER (Balaževic´等人,2019) 和 RotatE (Sun 等人,2019),其中 TuckER 是新添加的模型。对于(2)联合文本和图嵌入方法,我们评估了 RCNet (Xu等人,2014),TransE+LINE (Fu 等人,2019) 和 JointNRE (Han等人,2018)。对于(3)基于强化学习 (RL) 的路径查找方法,我们评估了 MINERVA (Das等人,2017) 和 CPL (Fu等人,2019)。对于(4)基于 PLM 的方法,我们评估了 PKGC (Lv等人,2022) 和我们的方法 TAGREAL。我们保留了 Fu等人2019报告的(2)和(3)的数据,同时重新评估所有的。
结果
我们在表1和表2中展示了与最先进方法的性能比较。正如人们可以观察到的,TAGREAL在大多数情况下都超过了现有的工作。在给定密集的训练数据的情况下,基于KGE的方法(例如,RotatE)和基于RL的方法(例如,CPL)仍然可以达到相对较高的性能。然而,当训练数据有限时,这些方法遇到困难,而基于PLM的方法(PKGC和TAGREAL)受到的影响不大。在这种情况下,我们的方法明显优于当前的非基于PLM的方法。这是因为KGE模型在数据不足的情况下无法有效地进行训练,基于RL的路径查找模型在KG中没有足够的证据和通用路径时无法识别出潜在的模式。另一方面,PLM已经拥有可以直接使用的隐含信息,微调时数据不足的负面影响会比从零开始训练要小得多。TAGREAL由于其能够自动挖掘高质量提示和检索支持信息的能力,而超过PKGC,与此相反的是,手动注释通常是有限的。
4. 结论
在这项研究中,我们提出了一个新颖的框架,利用PLM中的隐含知识进行开放的KG补全。实验结果显示,我们的方法在训练数据有限的情况下,表现优于现有的方法。我们证明了我们的方法优化的提示在PLM知识探测中优于手工制作的提示。支持信息检索对于辅助提示的有效性也得到了证明。在未来,我们可能会利用QA模型的能力来检索更可靠的支持信息。另一个潜在的扩展是通过探索路径查找任务,使我们的模型更具可解释性。



