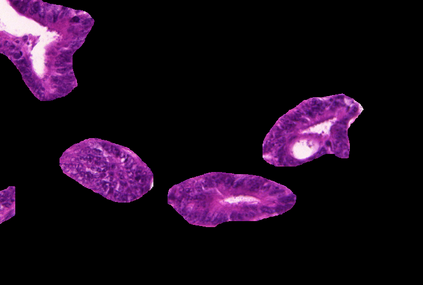
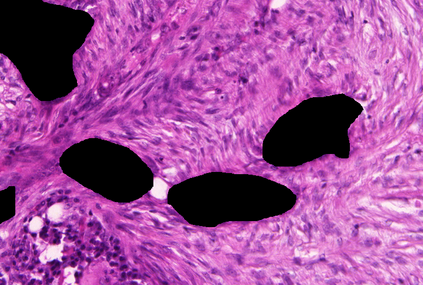
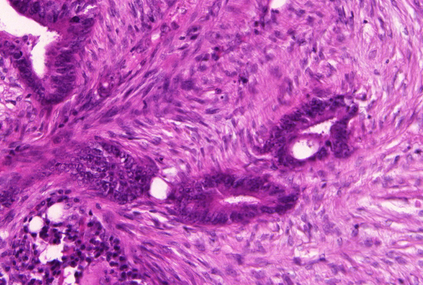
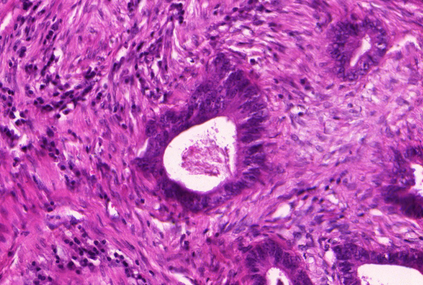
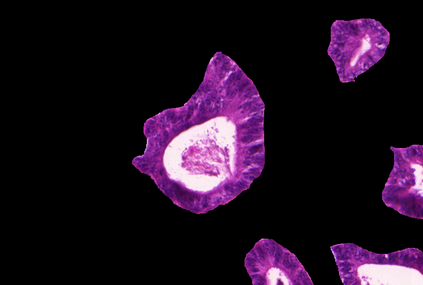
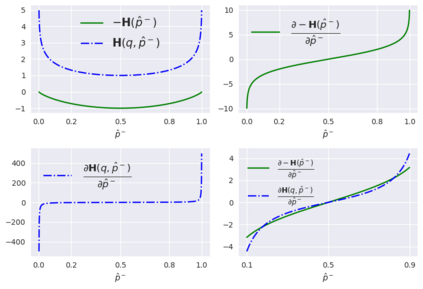
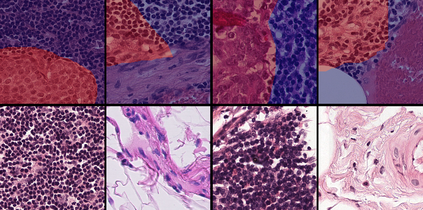
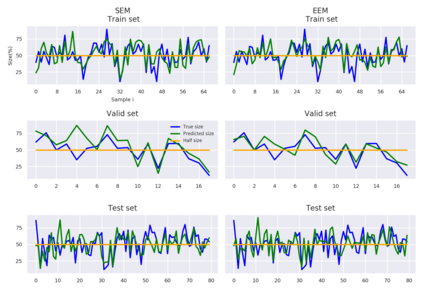
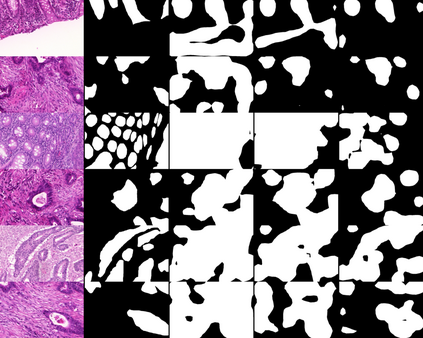
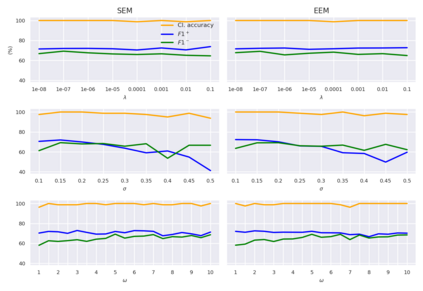
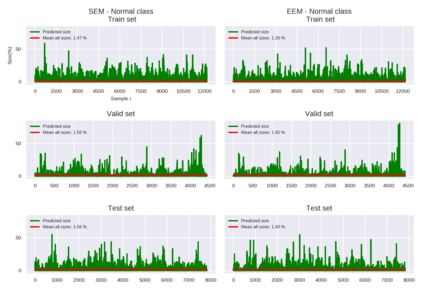
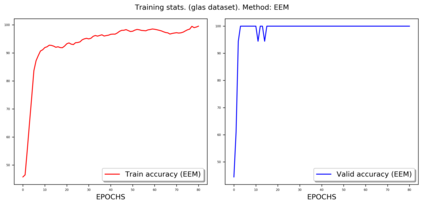
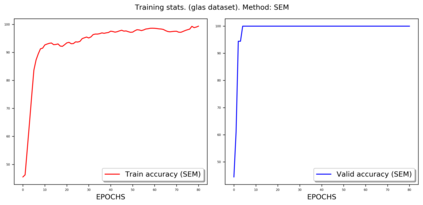
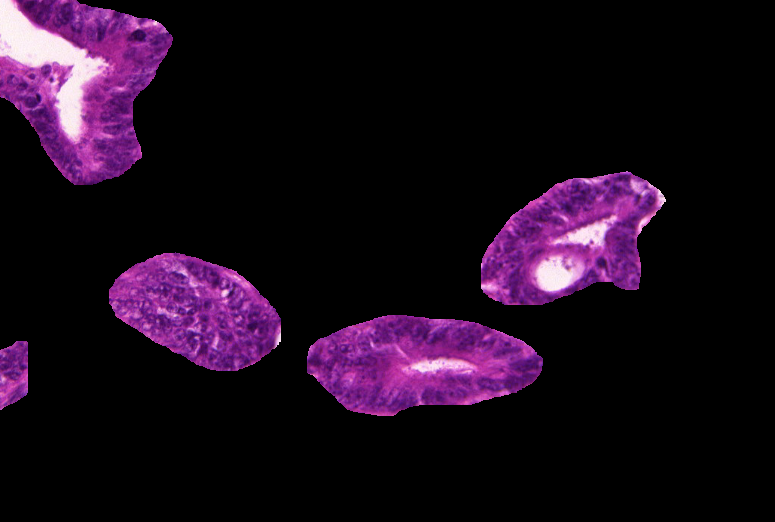
Weakly-supervised learning (WSL) has recently triggered substantial interest as it mitigates the lack of pixel-wise annotations. Given global image labels, WSL methods yield pixel-level predictions (segmentations), which enable to interpret class predictions. Despite their recent success, mostly with natural images, such methods can face important challenges when the foreground and background regions have similar visual cues, yielding high false-positive rates in segmentations, as is the case in challenging histology images. WSL training is commonly driven by standard classification losses, which implicitly maximize model confidence, and locate the discriminative regions linked to classification decisions. Therefore, they lack mechanisms for modeling explicitly non-discriminative regions and reducing false-positive rates. We propose novel regularization terms, which enable the model to seek both non-discriminative and discriminative regions, while discouraging unbalanced segmentations. We introduce high uncertainty as a criterion to localize non-discriminative regions that do not affect classifier decision, and describe it with original Kullback-Leibler (KL) divergence losses evaluating the deviation of posterior predictions from the uniform distribution. Our KL terms encourage high uncertainty of the model when the latter inputs the latent non-discriminative regions. Our loss integrates: (i) a cross-entropy seeking a foreground, where model confidence about class prediction is high; (ii) a KL regularizer seeking a background, where model uncertainty is high; and (iii) log-barrier terms discouraging unbalanced segmentations. Comprehensive experiments and ablation studies over the public GlaS colon cancer data and a Camelyon16 patch-based benchmark for breast cancer show substantial improvements over state-of-the-art WSL methods, and confirm the effect of our new regularizers.
翻译:微弱监督的学习( WSSL ) 最近引发了巨大的兴趣, 因为它缓解了像素分解说明的缺乏。 鉴于全球图像标签, WSL 方法产生了像素级预测( 分化), 能够解释类预测。 尽管这些方法最近取得了成功, 大多使用自然图像, 但是当前方和背景区域有相似的视觉提示, 导致偏差率高, 导致偏差率高。 WSL 培训通常受到标准分类损失的驱动, 这些损失隐含着最大限度地增强模型信心, 以及定位与分类决定相关的歧视区域。 因此, WSLSL 方法缺乏构建清晰的像素级预测( 分化), 并减少错误率率。 我们提出了新的身份规范术语, 使模型能够寻求非偏差性和偏差性区域, 同时抑制偏差的偏差分。 我们引入了一个标准, 不至偏差的数值区域( 不至偏差的正反正值 ), 并用原始的KRevreal- Lei( KL) 类) 定值分析值的分解结果, 来评估我们的直线值数据在后演变差 。