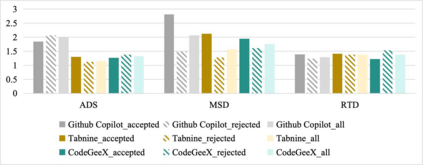
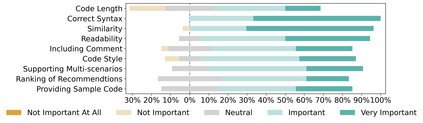
Recent In-IDE AI coding assistant tools (ACATs) like GitHub Copilot have significantly impacted developers' coding habits. While some studies have examined their effectiveness, there lacks in-depth investigation into the actual assistance process. To bridge this gap, we simulate real development scenarios encompassing three typical types of software development tasks and recruit 27 computer science students to investigate their behavior with three popular ACATs. Our goal is to comprehensively assess ACATs' effectiveness, explore characteristics of recommended code, identify reasons for modifications, and understand users' challenges and expectations. To facilitate the study, we develop an experimental platform that includes a data collection plugin for VSCode IDE and provides functions for screen recording, code evaluation, and automatic generation of personalized interview and survey questions. Through analysis of the collected data, we find that ACATs generally enhance task completion rates, reduce time, improve code quality, and increase self-perceived productivity. However, the improvement is influenced by both the nature of coding tasks and users' experience level. Notably, for experienced participants, the use of ACATs may even increase completion time. We observe that "edited line completion" is the most frequently recommended way, while "comments completion" and "string completion" have the lowest acceptance rates. The primary reasons for modifying recommended code are disparities between output formats and requirements, flawed logic, and inconsistent code styles. In terms of challenges and expectations, optimization of service access and help documentation is also concerned by participants except for functionality and performance. Our study provides valuable insights into the effectiveness and usability of ACATs, informing further improvements in their design and implementation.
翻译:暂无翻译