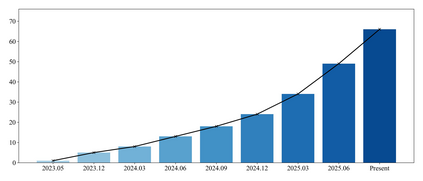
Diffusion Models have become a cornerstone of modern generative AI for their exceptional generation quality and controllability. However, their inherent \textit{multi-step iterations} and \textit{complex backbone networks} lead to prohibitive computational overhead and generation latency, forming a major bottleneck for real-time applications. Although existing acceleration techniques have made progress, they still face challenges such as limited applicability, high training costs, or quality degradation. Against this backdrop, \textbf{Diffusion Caching} offers a promising training-free, architecture-agnostic, and efficient inference paradigm. Its core mechanism identifies and reuses intrinsic computational redundancies in the diffusion process. By enabling feature-level cross-step reuse and inter-layer scheduling, it reduces computation without modifying model parameters. This paper systematically reviews the theoretical foundations and evolution of Diffusion Caching and proposes a unified framework for its classification and analysis. Through comparative analysis of representative methods, we show that Diffusion Caching evolves from \textit{static reuse} to \textit{dynamic prediction}. This trend enhances caching flexibility across diverse tasks and enables integration with other acceleration techniques such as sampling optimization and model distillation, paving the way for a unified, efficient inference framework for future multimodal and interactive applications. We argue that this paradigm will become a key enabler of real-time and efficient generative AI, injecting new vitality into both theory and practice of \textit{Efficient Generative Intelligence}.
翻译:暂无翻译