
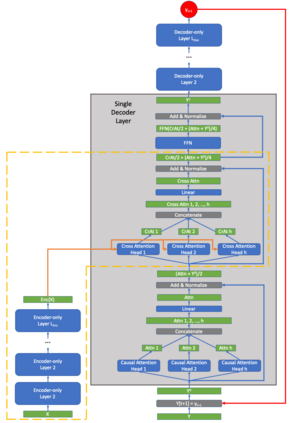
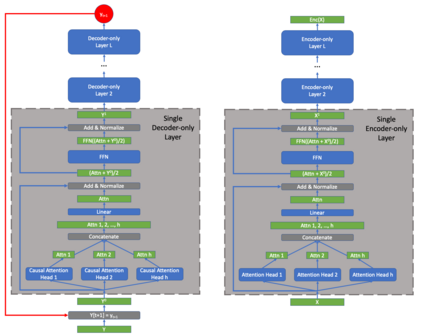
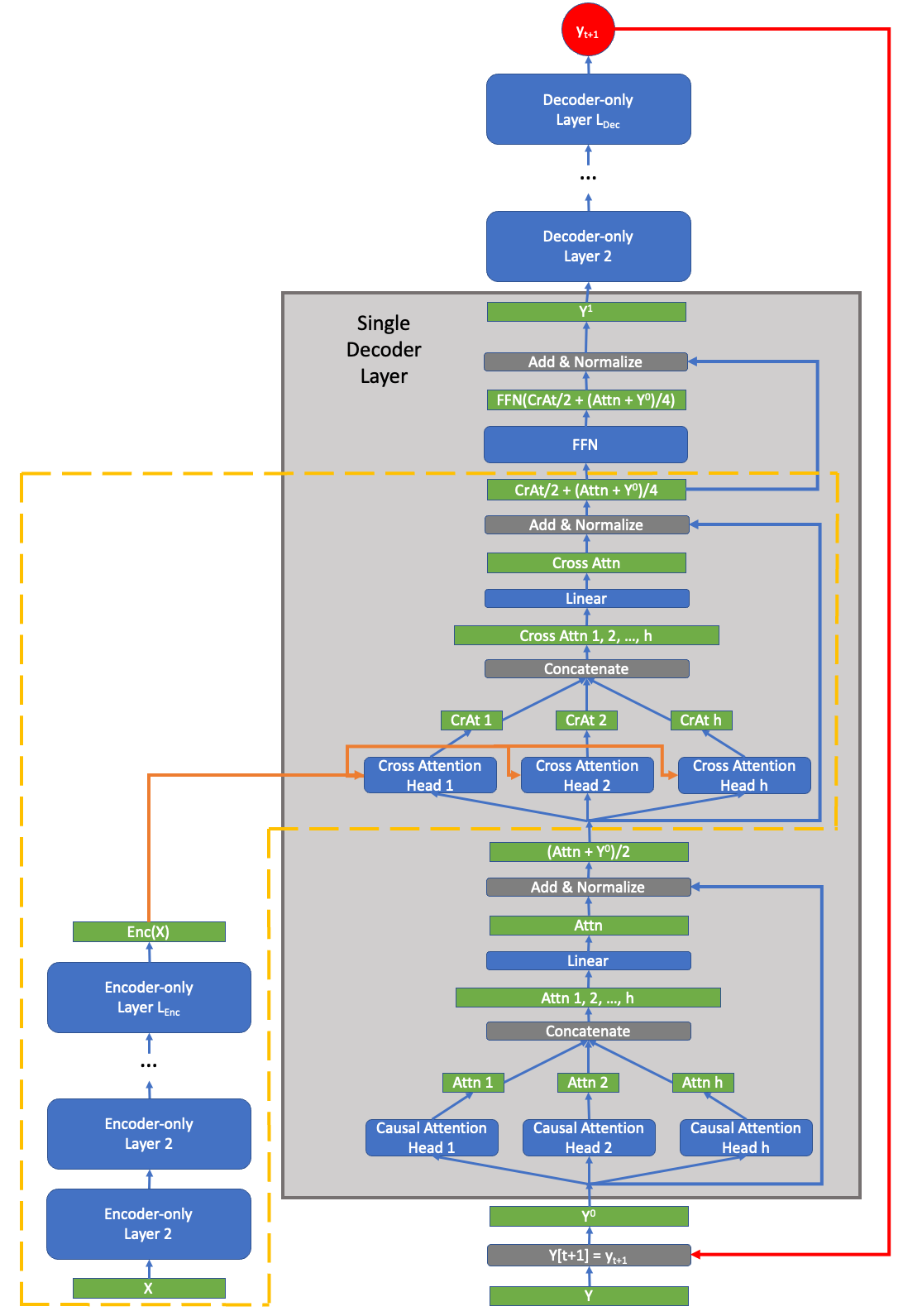
In this article we prove that the general transformer neural model undergirding modern large language models (LLMs) is Turing complete under reasonable assumptions. This is the first work to directly address the Turing completeness of the underlying technology employed in GPT-x as past work has focused on the more expressive, full auto-encoder transformer architecture. From this theoretical analysis, we show that the sparsity/compressibility of the word embedding is an important consideration for Turing completeness to hold. We also show that Transformers are are a variant of B machines studied by Hao Wang.
翻译:暂无翻译
相关内容

专知会员服务
34+阅读 · 2019年10月18日
专知会员服务
36+阅读 · 2019年10月17日
Arxiv
0+阅读 · 2024年3月15日
Arxiv
0+阅读 · 2024年3月13日



相关VIP内容
专知会员服务
34+阅读 · 2019年10月18日
专知会员服务
36+阅读 · 2019年10月17日
相关资讯
相关论文
Arxiv
0+阅读 · 2024年3月15日
Arxiv
0+阅读 · 2024年3月13日