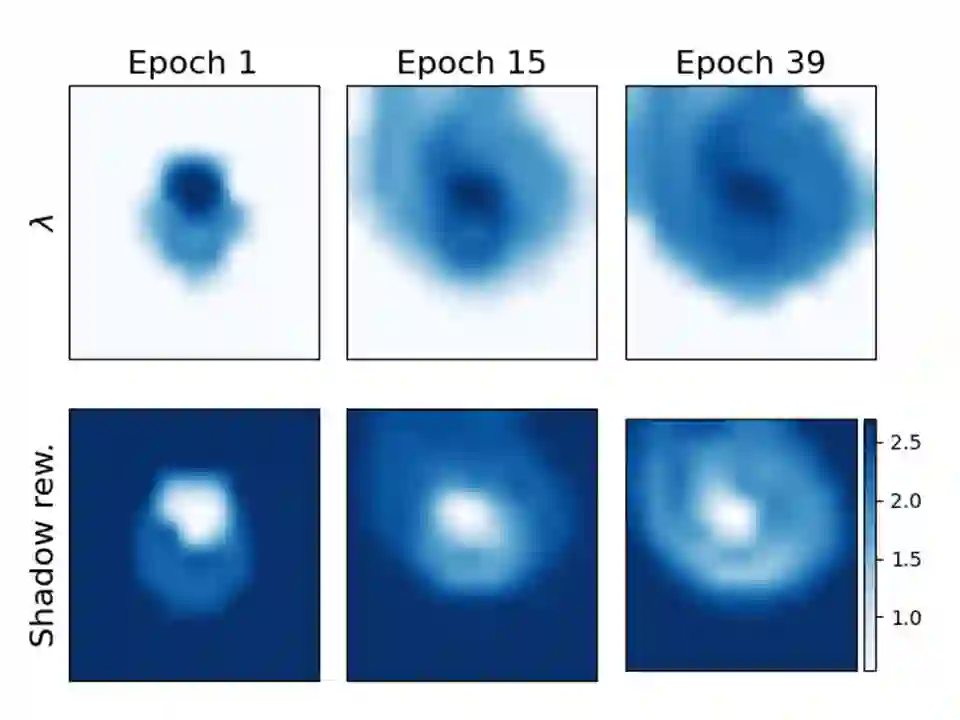
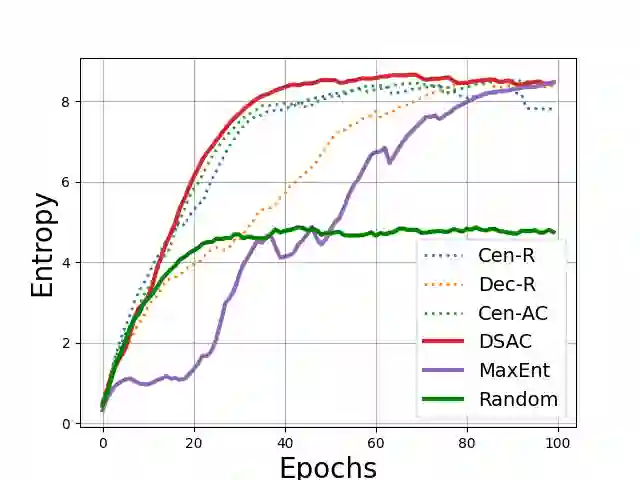
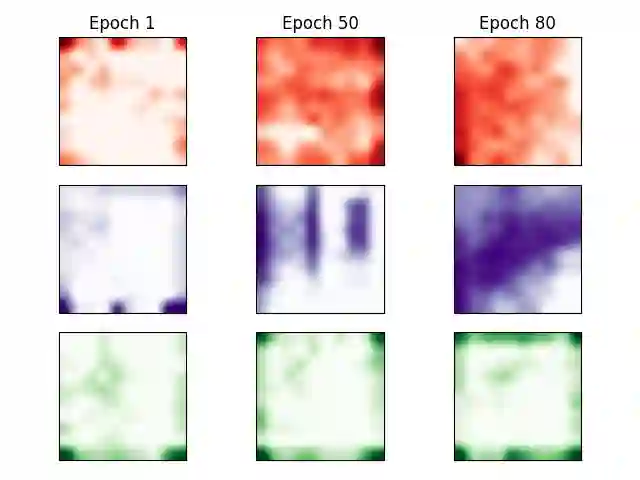
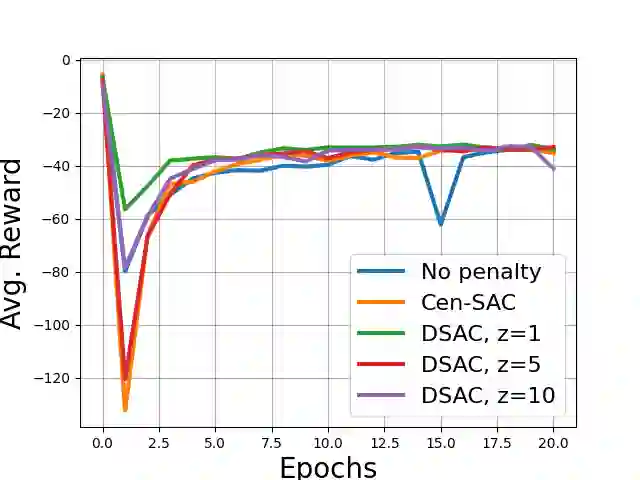
We posit a new mechanism for cooperation in multi-agent reinforcement learning (MARL) based upon any nonlinear function of the team's long-term state-action occupancy measure, i.e., a \emph{general utility}. This subsumes the cumulative return but also allows one to incorporate risk-sensitivity, exploration, and priors. % We derive the {\bf D}ecentralized {\bf S}hadow Reward {\bf A}ctor-{\bf C}ritic (DSAC) in which agents alternate between policy evaluation (critic), weighted averaging with neighbors (information mixing), and local gradient updates for their policy parameters (actor). DSAC augments the classic critic step by requiring agents to (i) estimate their local occupancy measure in order to (ii) estimate the derivative of the local utility with respect to their occupancy measure, i.e., the "shadow reward". DSAC converges to $\epsilon$-stationarity in $\mathcal{O}(1/\epsilon^{2.5})$ (Theorem \ref{theorem:final}) or faster $\mathcal{O}(1/\epsilon^{2})$ (Corollary \ref{corollary:communication}) steps with high probability, depending on the amount of communications. We further establish the non-existence of spurious stationary points for this problem, that is, DSAC finds the globally optimal policy (Corollary \ref{corollary:global}). Experiments demonstrate the merits of goals beyond the cumulative return in cooperative MARL.
翻译:我们根据多试剂强化学习(MARL)中的任何非线性功能, 即 \ emph{ 通用工具}, 建立一个新的合作机制, 在多试剂强化学习( MARL ) 中, 以团队长期国家行动占用度值的非线性功能, 即 \ emph{ 通用工具} 为基础。 这个机制将累积累积累积回报, 并允许其中包含风险敏感性、 探索和前缀 。% 我们得出 \ bf D} 集中化的 { bf S} 奖赏 。 DSAC 在政策评估( critical) (cal) 与邻居( 信息混合) 和本地梯度更新政策参数( actor) 。 DSAC 通过要求代理( i) 估计其本地占用度的衍生值, 也就是“ 影子奖赏 ” 。 DSAC 在 $\ mall 中, ( Thereem\\\ coloralal) lex: the coloral deal developlegle: the ral deal deal deal deal riotal ral ral rize:: =oal =oal =oal =oal=oal =oal=oal=oal=oal= = = =oal=美元=美元=美元=美元=美元。