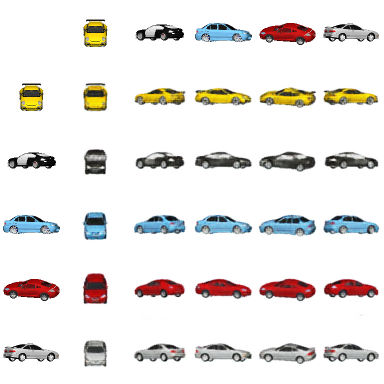
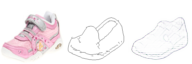
Content and style (C-S) disentanglement intends to decompose the underlying explanatory factors of objects into two independent subspaces. From the unsupervised disentanglement perspective, we rethink content and style and propose a formulation for unsupervised C-S disentanglement based on our assumption that different factors are of different importance and popularity for image reconstruction, which serves as a data bias. The corresponding model inductive bias is introduced by our proposed C-S disentanglement Module (C-S DisMo), which assigns different and independent roles to content and style when approximating the real data distributions. Specifically, each content embedding from the dataset, which encodes the most dominant factors for image reconstruction, is assumed to be sampled from a shared distribution across the dataset. The style embedding for a particular image, encoding the remaining factors, is used to customize the shared distribution through an affine transformation. The experiments on several popular datasets demonstrate that our method achieves the state-of-the-art unsupervised C-S disentanglement, which is comparable or even better than supervised methods. We verify the effectiveness of our method by downstream tasks: domain translation and single-view 3D reconstruction. Project page at https://github.com/xrenaa/CS-DisMo.
翻译:内容和风格( C- S) 解析( C- S) 解析模式旨在将对象的基本解释性因素分解为两个独立的子空间。 从未受监督的分解角度,我们重新思考内容和风格,并根据以下假设提出未经监督的 C- S 分解的配方,即不同因素对于图像重建的不同重要性和受欢迎程度,这起到了数据偏差的作用。相应的导导导偏模型是通过我们提议的 C- S 分解模块( C- S Dismo) 引入的,该模块在接近真实数据分布时,对内容和风格分配不同和独立的角色。具体地说,从数据集中嵌入的每个内容都包含着图像重建的最主要因素,我们假设它们从数据集的共享分布中抽样。 嵌入特定图像的风格,将剩余因素结合成数据偏差。 几个流行数据集的实验表明,我们的方法达到了最先进的状态和不受监督的 C- S- S- 分解性模式。 具体地说, 数据集中的每个嵌嵌入内容都具有可比性, 或域域内更精确的版本 。 我们的版本/ CS- d- 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校 校