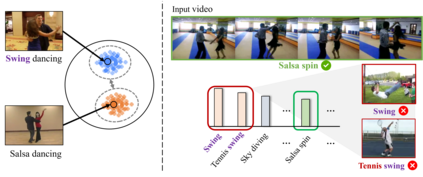
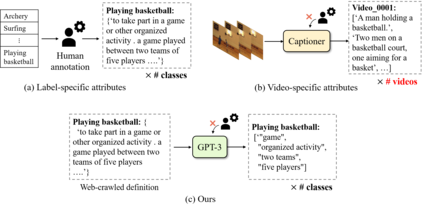
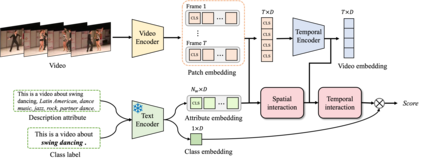
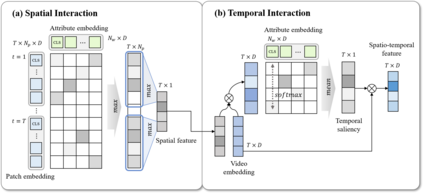
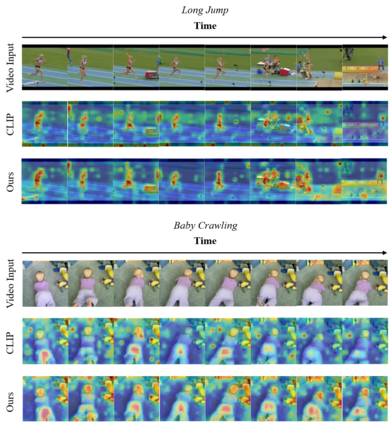
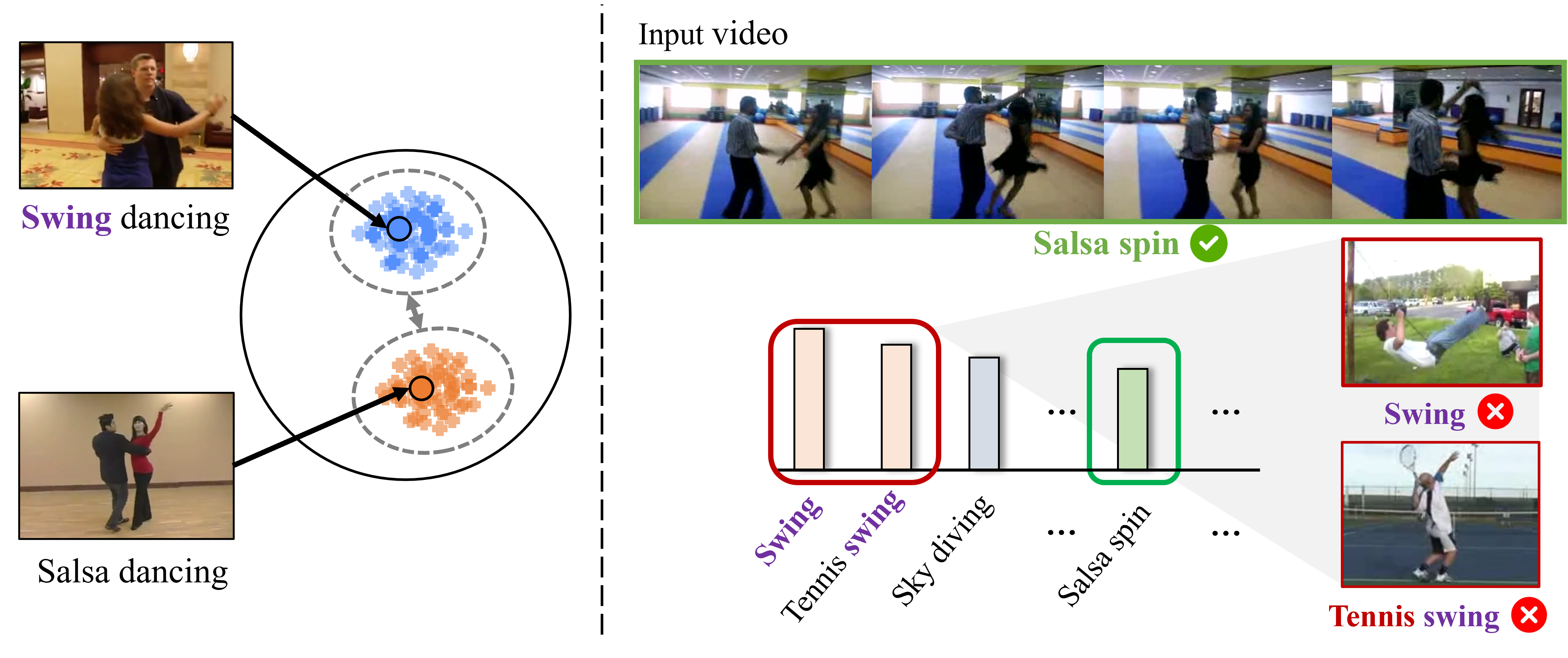
Vision-Language Models (VLMs) have demonstrated impressive capabilities in zero-shot action recognition by learning to associate video embeddings with class embeddings. However, a significant challenge arises when relying solely on action classes to provide semantic context, particularly due to the presence of multi-semantic words, which can introduce ambiguity in understanding the intended concepts of actions. To address this issue, we propose an innovative approach that harnesses web-crawled descriptions, leveraging a large-language model to extract relevant keywords. This method reduces the need for human annotators and eliminates the laborious manual process of attribute data creation. Additionally, we introduce a spatio-temporal interaction module designed to focus on objects and action units, facilitating alignment between description attributes and video content. In our zero-shot experiments, our model achieves impressive results, attaining accuracies of 81.0%, 53.1%, and 68.9% on UCF-101, HMDB-51, and Kinetics-600, respectively, underscoring the model's adaptability and effectiveness across various downstream tasks.
翻译:暂无翻译