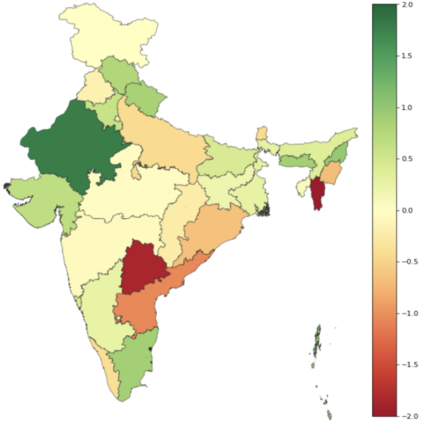
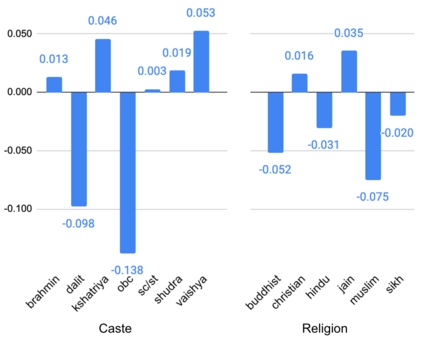
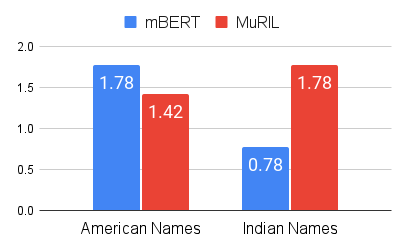
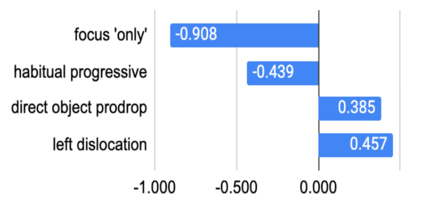
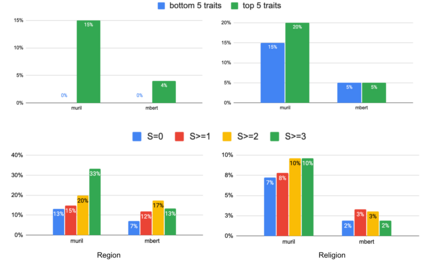
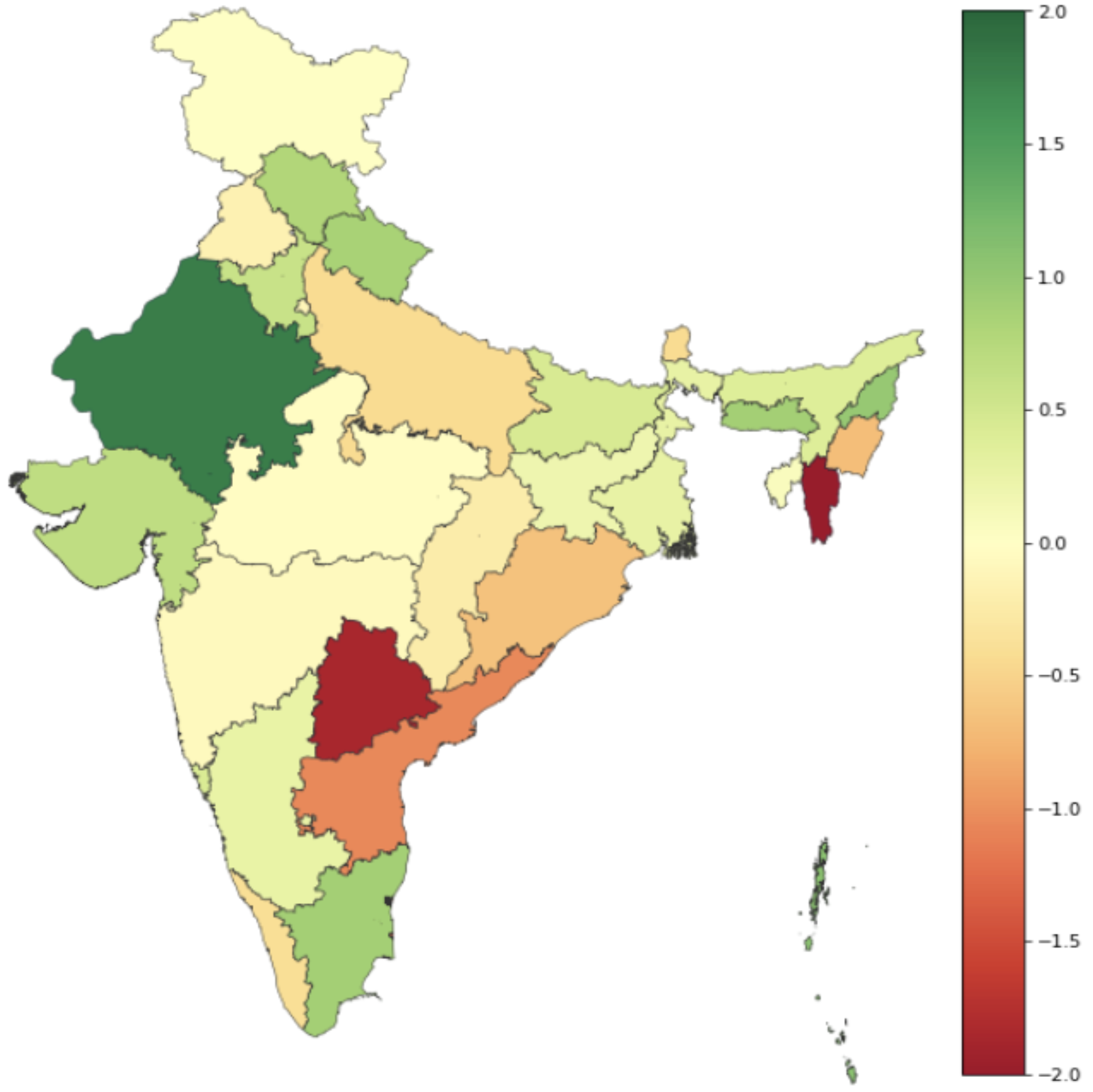
Recent research has revealed undesirable biases in NLP data & models. However, these efforts focus of social disparities in West, and are not directly portable to other geo-cultural contexts. In this paper, we focus on NLP fairness in the context of India. We start with a brief account of prominent axes of social disparities in India. We build resources for fairness evaluation in the Indian context and use them to demonstrate prediction biases along some of the axes. We then delve deeper into social stereotypes for Region & Religion, demonstrating its prevalence in corpora & models. Finally, we outline a holistic research agenda to re-contextualize NLP fairness research for the Indian context, accounting for Indian societal context, bridging technological gaps in capability, resources, and adapting to Indian cultural values. While we focus on 'India' here, this framework can be generalized for recontextualization in other geo-cultural contexts.
翻译:最近的研究揭示了NLP数据和模型中的不良偏差。然而,这些努力的重点是西方的社会差异,不能直接被其他地理文化背景所接受。在本文中,我们侧重于印度的NLP公平性。我们首先简要介绍印度社会差异的突出轴心。我们为在印度的公平性评估建立了资源,并用这些资源来展示一些轴心的预测偏差。我们接着深入探讨地区和宗教的社会陈规定型观念,以展示其在公司和模型中的流行程度。最后,我们概述了一项综合研究议程,以重新将NLP公平性研究转化为印度背景,为印度社会背景进行核算,弥合能力、资源方面的技术差距,并适应印度的文化价值。我们在这里侧重于“印度”时,这个框架可以被普遍化,用于在其他地理文化背景下的重新通俗化。