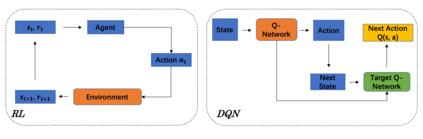
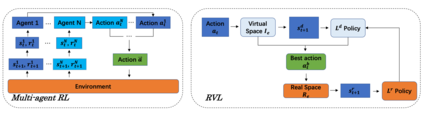
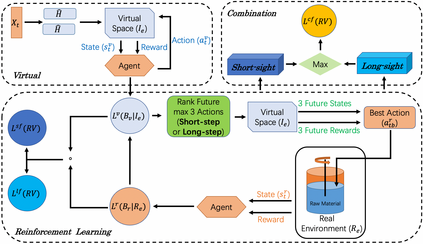
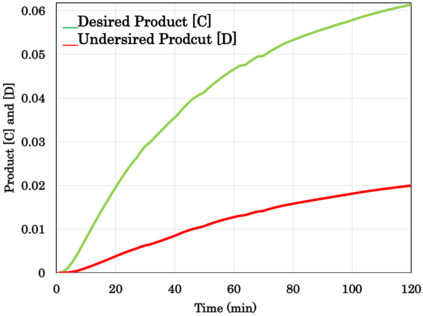
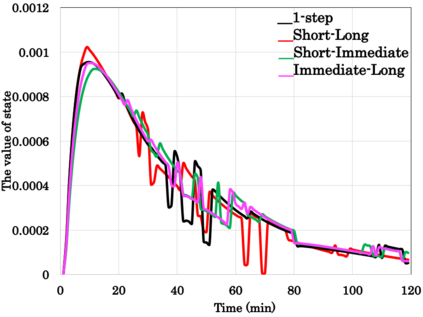
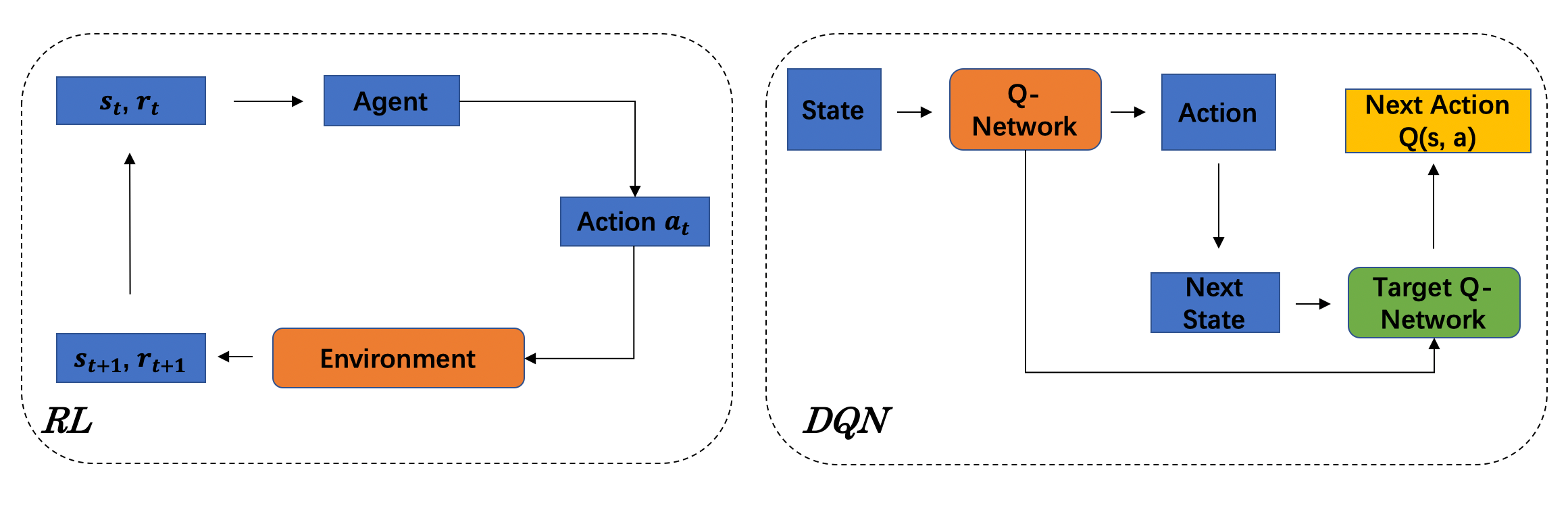
Reinforcement Learning (RL)-based control system has received considerable attention in recent decades. However, in many real-world problems, such as Batch Process Control, the environment is uncertain, which requires expensive interaction to acquire the state and reward values. In this paper, we present a cost-efficient framework, such that the RL model can evolve for itself in a Virtual Space using the predictive models with only historical data. The proposed framework enables a step-by-step RL model to predict the future state and select optimal actions for long-sight decisions. The main focuses are summarized as: 1) how to balance the long-sight and short-sight rewards with an optimal strategy; 2) how to make the virtual model interacting with real environment to converge to a final learning policy. Under the experimental settings of Fed-Batch Process, our method consistently outperforms the existing state-of-the-art methods.
翻译:近几十年来,基于强化学习(RL)的控制系统受到相当多的关注,然而,在许多现实世界的问题中,如批量过程控制,环境是不确定的,这需要花费昂贵的互动才能获得状态和奖励价值。在本文件中,我们提出了一个成本效率高的框架,这样RL模型就可以在虚拟空间中利用仅具有历史数据的预测模型自我演化。拟议的框架使得逐步的RL模型能够预测未来状况,并为长期观察的决定选择最佳行动。主要重点被概括为:(1) 如何平衡长视和短视的回报与最佳战略;(2) 如何使虚拟模型与实际环境互动,以便形成最终的学习政策。在美联储-批量过程的实验环境中,我们的方法始终超越了现有的最新方法。