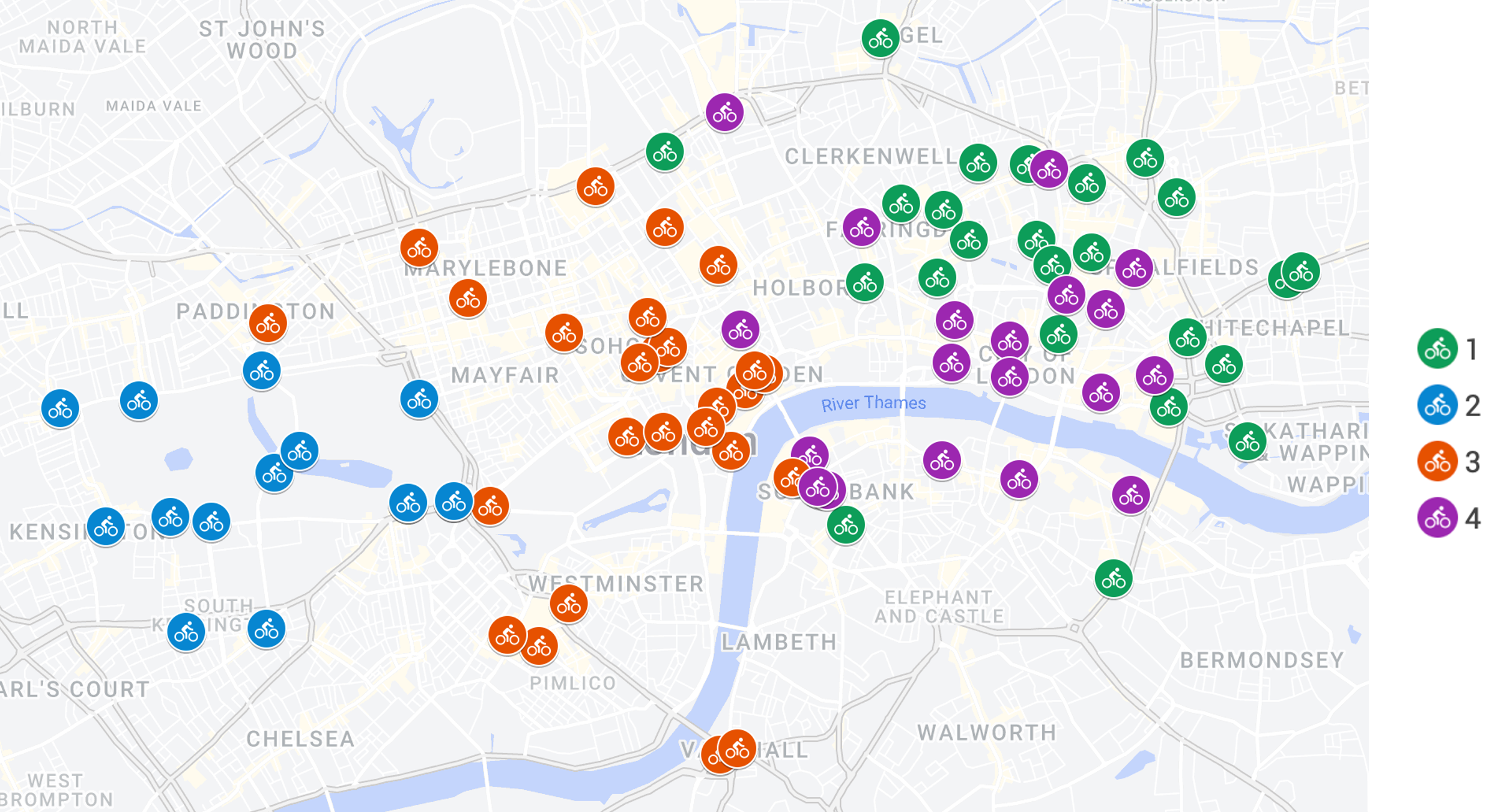
Network data are observed in various applications where the individual entities of the system interact with or are connected to each other, and often these interactions are defined by their associated strength or importance. Clustering is a common task in network analysis that involves finding groups of nodes displaying similarities in the way they interact with the rest of the network. However, most clustering methods use the strengths of connections between entities in their original form, ignoring the possible differences in the capacities of individual nodes to send or receive edges. This often leads to clustering solutions that are heavily influenced by the nodes' capacities. One way to overcome this is to analyse the strengths of connections in relative rather than absolute terms, expressing each edge weight as a proportion of the sending (or receiving) capacity of the respective node. This, however, induces additional modelling constraints that most existing clustering methods are not designed to handle. In this work we propose a stochastic block model for composition-weighted networks based on direct modelling of compositional weight vectors using a Dirichlet mixture, with the parameters determined by the cluster labels of the sender and the receiver nodes. Inference is implemented via an extension of the classification expectation-maximisation algorithm that uses a working independence assumption, expressing the complete data likelihood of each node of the network as a function of fixed cluster labels of the remaining nodes. A model selection criterion is derived to aid the choice of the number of clusters. The model is validated using simulation studies, and showcased on network data from the Erasmus exchange program and a bike sharing network for the city of London.
翻译:暂无翻译