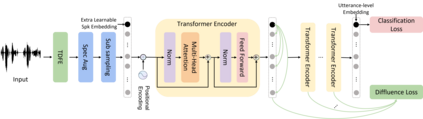
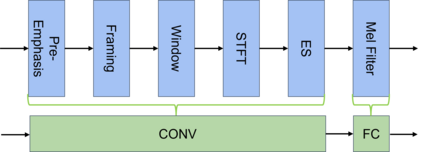
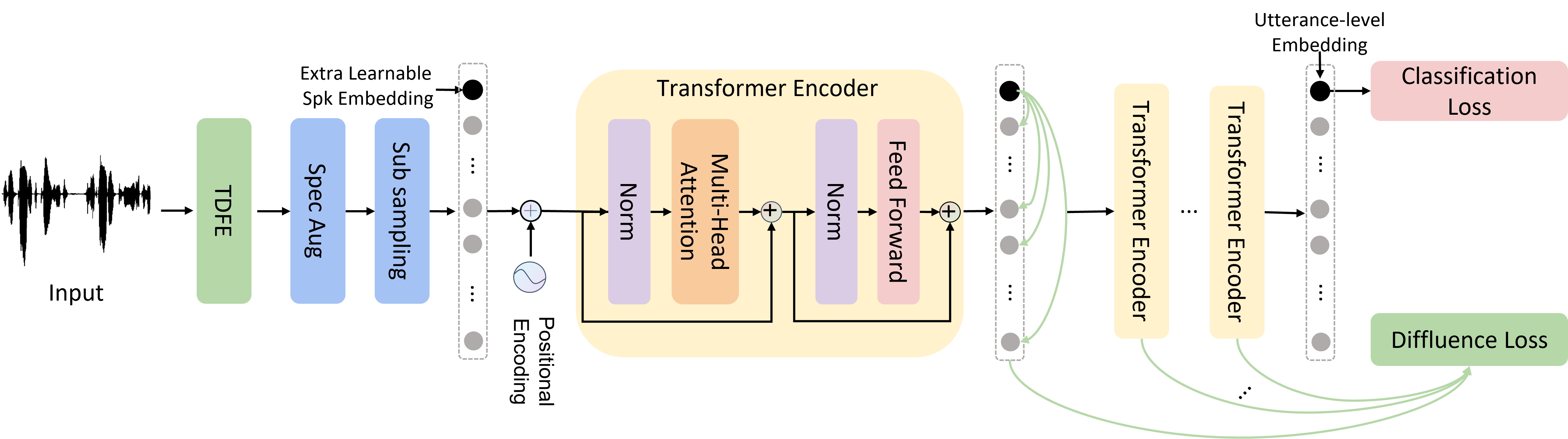
Speaker verification (SV) aims to determine whether the speaker's identity of a test utterance is the same as the reference speech. In the past few years, extracting speaker embeddings using deep neural networks for SV systems has gone mainstream. Recently, different attention mechanisms and Transformer networks have been explored widely in SV fields. However, utilizing the original Transformer in SV directly may have frame-level information waste on output features, which could lead to restrictions on capacity and discrimination of speaker embeddings. Therefore, we propose an approach to derive utterance-level speaker embeddings via a Transformer architecture that uses a novel loss function named diffluence loss to integrate the feature information of different Transformer layers. Therein, the diffluence loss aims to aggregate frame-level features into an utterance-level representation, and it could be integrated into the Transformer expediently. Besides, we also introduce a learnable mel-fbank energy feature extractor named time-domain feature extractor that computes the mel-fbank features more precisely and efficiently than the standard mel-fbank extractor. Combining Diffluence loss and Time-domain feature extractor, we propose a novel Transformer-based time-domain SV model (DT-SV) with faster training speed and higher accuracy. Experiments indicate that our proposed model can achieve better performance in comparison with other models.
翻译:音员校验( SV) 的目的是确定演讲人测试语句的特性是否与参考语句相同。 在过去几年中,利用SV系统深神经网络将演讲人嵌入的深神经网进行抽取,在SV字段中最近广泛探索了不同的关注机制和变换器网络。然而,直接利用SV原有的变换器可能会产生关于产出特性的框架级信息浪费,这可能导致限制演讲人嵌入的能力和歧视。因此,我们建议采用一种方法,通过一个使用名为 diffluence 损失的新式损失函数将不同变换器层的特征信息纳入主流的变换器结构来产生发音级演讲人层。 由此, diffluence 损失的目的是将总体框架级特征纳入一个全局层面的表述中,并且可以快速地将其纳入变换换器中。 此外,我们还引入了一种可学习的中流式银行能源特征提取器,名为时间- 位模型提取器,比标准的Mel- 银行提取器提取器更精确和高效地将不同变换速度模型与Simdustrual- developmentS- developmental- developmental- developmental- dex- developmentaltravelopmental- dex- developmental- developmental- develgistrations