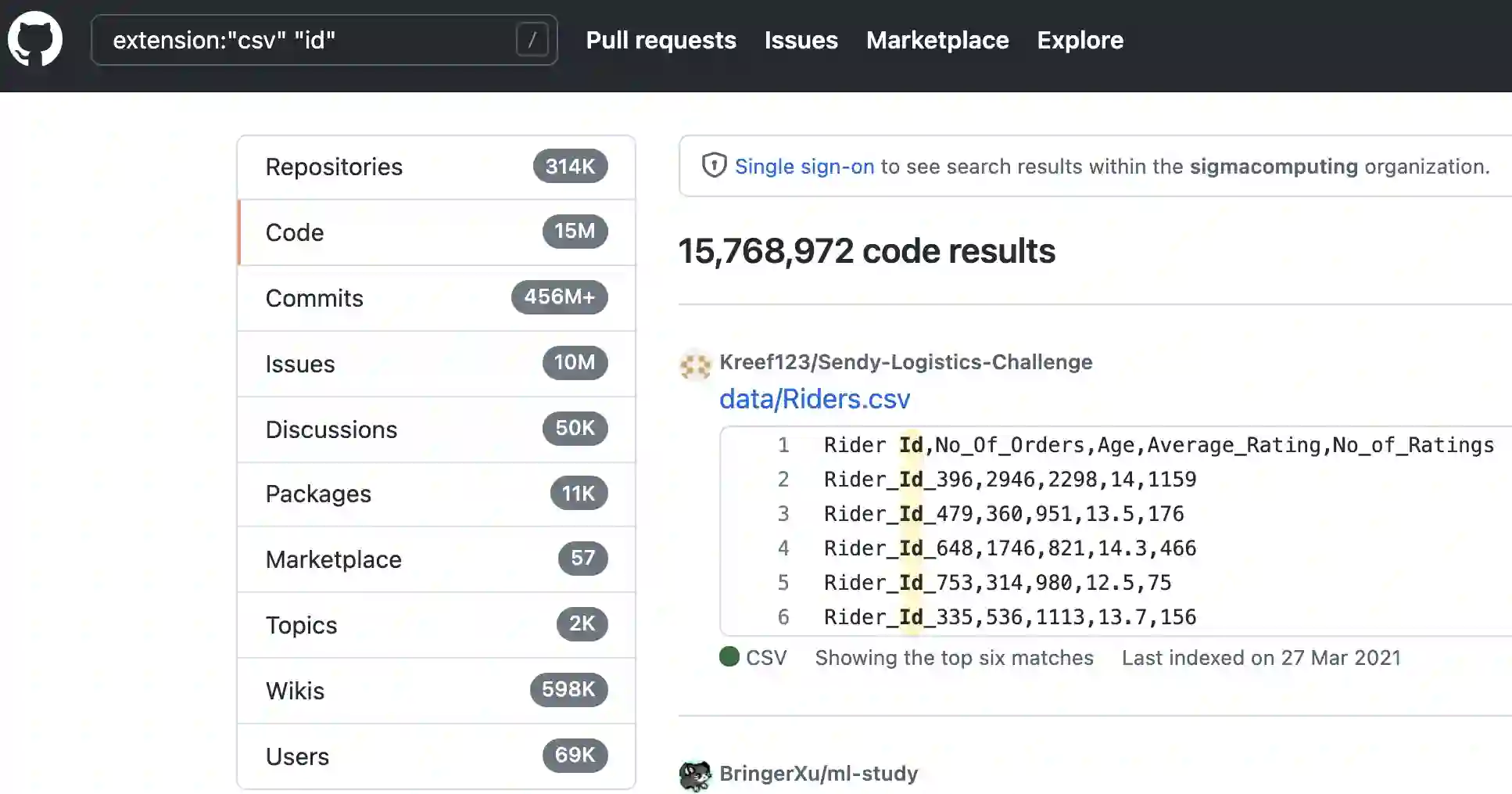
The success of deep learning has sparked interest in improving relational table tasks, like data preparation and search, with table representation models trained on large table corpora. Existing table corpora primarily contain tables extracted from HTML pages, limiting the capability to represent offline database tables. To train and evaluate high-capacity models for applications beyond the Web, we need resources with tables that resemble relational database tables. Here we introduce GitTables, a corpus of 1M relational tables extracted from GitHub. Our continuing curation aims at growing the corpus to at least 10M tables. Analyses of GitTables show that its structure, content, and topical coverage differ significantly from existing table corpora. We annotate table columns in GitTables with semantic types, hierarchical relations and descriptions from Schema.org and DBpedia. The evaluation of our annotation pipeline on the T2Dv2 benchmark illustrates that our approach provides results on par with human annotations. We present three applications of GitTables, demonstrating its value for learned semantic type detection models, schema completion methods, and benchmarks for table-to-KG matching, data search, and preparation. We make the corpus and code available at https://gittables.github.io.
翻译:深层学习的成功激发了人们对改进关系表任务的兴趣,例如数据编制和搜索,在大表公司上培训了表代表模型。现有表公司主要包含从HTML网页上提取的表格,限制了代表离线数据库表格的能力。为培训和评价网外应用的高能力模型,我们需要资源,表格与关系数据库表格相似。这里我们介绍GitTables,这是从GitHub提取的1M关系表的集合体。我们继续整理的目的是将材料增加到至少10M表。对GitTables的分析表明,其结构、内容和主题覆盖面与现有的表公司有很大不同。我们在Gittals中用语系类型、等级关系和Schema.org和DBpedia的描述来记录高能力模型列列。我们对T2Dv2基准上的注解管道的评价表明,我们的方法提供了与人文相近的结果。我们介绍了Gittals的三个应用程序,展示了它对于学习的语系类型探测模型、计划完成方法以及主题覆盖面与现有表格公司之间的价值。我们在表格-KGroads上进行数据搜索和基准。