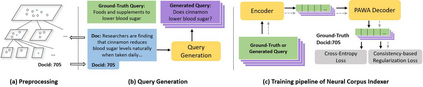
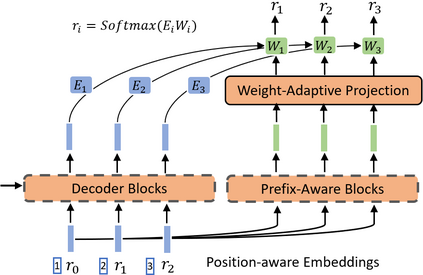
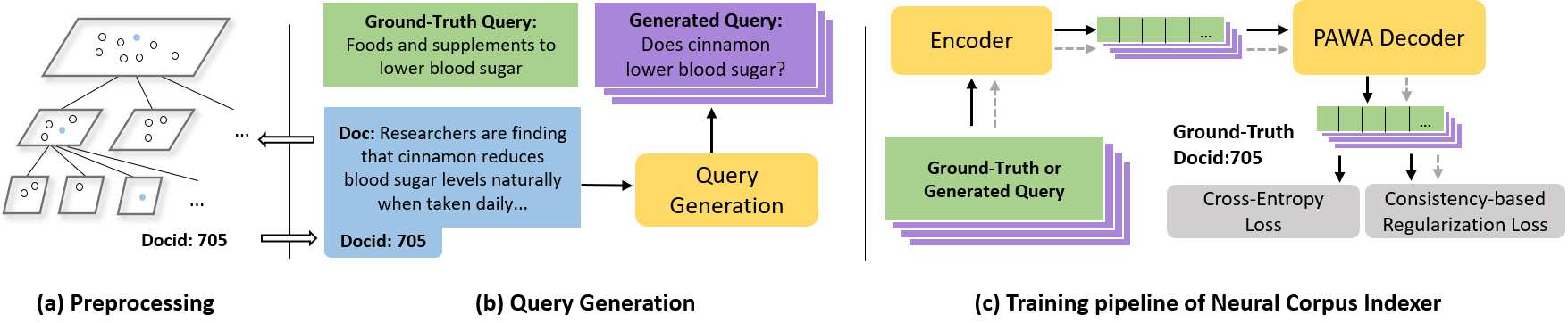
Current state-of-the-art document retrieval solutions mainly follow an index-retrieve paradigm, where the index is hard to be optimized for the final retrieval target. In this paper, we aim to show that an end-to-end deep neural network unifying training and indexing stages can significantly improve the recall performance of traditional methods. To this end, we propose Neural Corpus Indexer (NCI), a sequence-to-sequence network that generates relevant document identifiers directly for a designated query. To optimize the recall performance of NCI, we invent a prefix-aware weight-adaptive decoder architecture, and leverage tailored techniques including query generation, semantic document identifiers and consistency-based regularization. Empirical studies demonstrated the superiority of NCI on a commonly used academic benchmark, achieving +51.9% relative improvement on NQ320k dataset compared to the best baseline.
翻译:目前最先进的文档检索解决方案主要遵循指数-检索模式,其中索引很难优化,以达到最后检索目标。在本文中,我们的目标是显示一个端到端的深神经网络统一培训和指数化阶段可以大大改善传统方法的召回性能。为此,我们提议建立神经立体索引(NCI),一个序列到序列网络,直接为指定查询生成相关文件标识符。为了优化NCI的召回性能,我们发明了一个前等维瓦重量适应性脱coder结构,并利用了定制技术,包括生成查询、语义文件识别器和基于一致性的正规化。 经验学研究表明,NQ320数据集相对于最佳基线而言,NQ320数据集的相对改进率为51.9%。