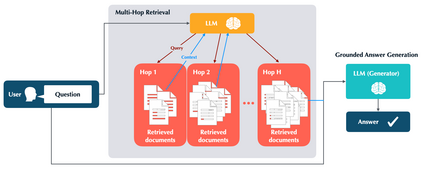
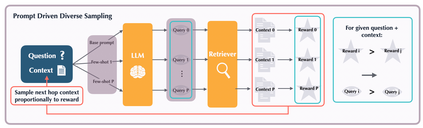
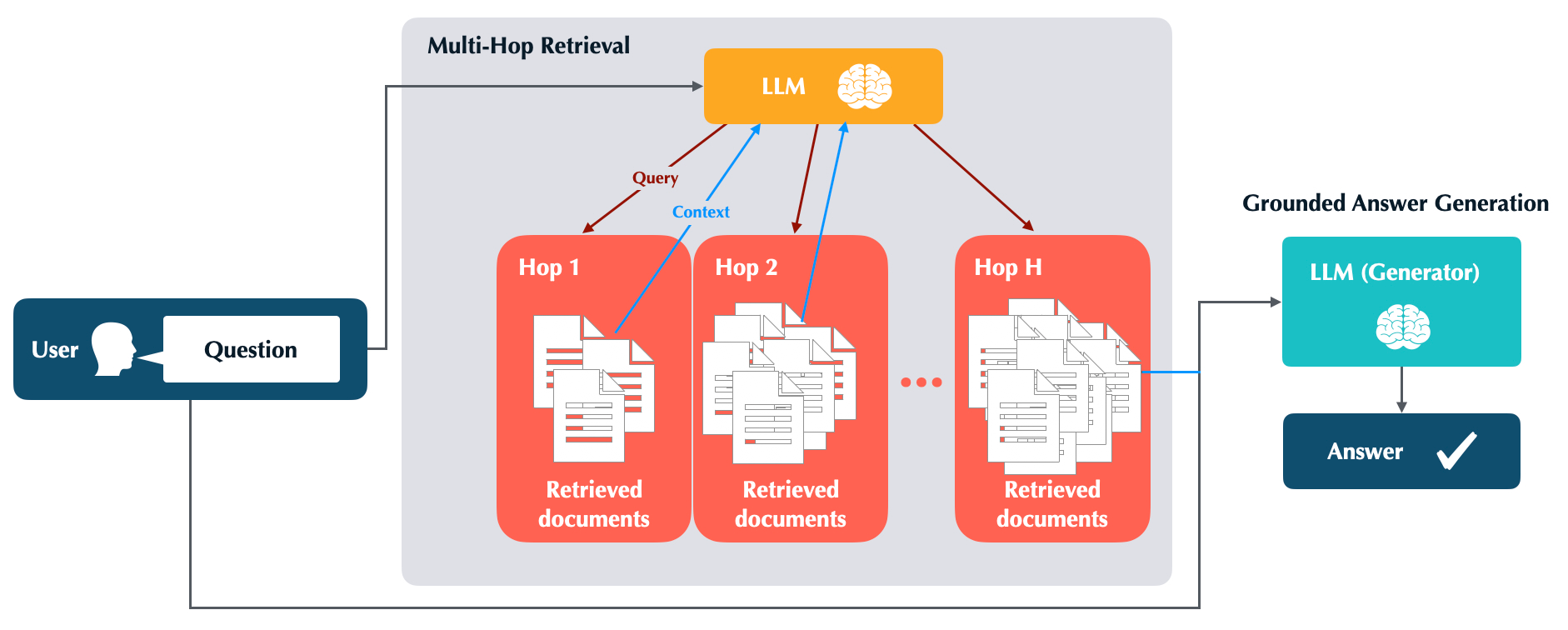
The hallucinations of large language models (LLMs) are increasingly mitigated by allowing LLMs to search for information and to ground their answers in real sources. Unfortunately, LLMs often struggle with posing the right search queries, especially when dealing with complex or otherwise indirect topics. Observing that LLMs can learn to search for relevant facts by $\textit{trying}$ different queries and learning to up-weight queries that successfully produce relevant results, we introduce $\underline{Le}$arning to $\underline{Re}$trieve by $\underline{T}$rying (LeReT), a reinforcement learning framework that explores search queries and uses preference-based optimization to improve their quality. \methodclass can improve the absolute retrieval accuracy by up to 29\% and the downstream generator evaluations by 17\%. The simplicity and flexibility of LeReT allows it to be applied to arbitrary off-the-shelf retrievers and makes it a promising technique for improving general LLM pipelines. Project website: http://sherylhsu.com/LeReT/.
翻译:暂无翻译