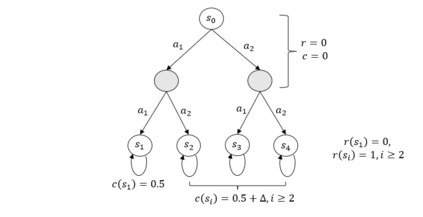
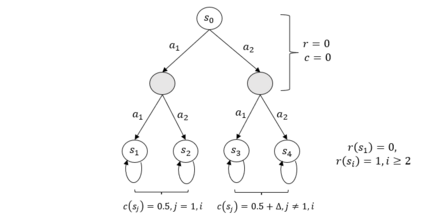
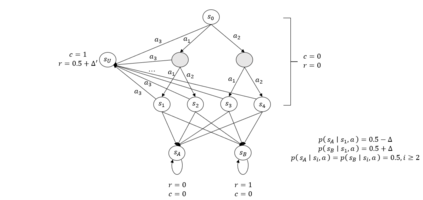
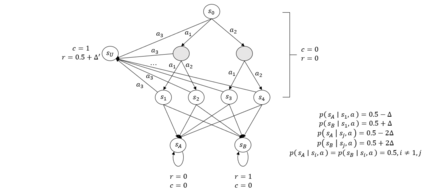
In this paper, we investigate a novel safe reinforcement learning problem with step-wise violation constraints. Our problem differs from existing works in that we consider stricter step-wise violation constraints and do not assume the existence of safe actions, making our formulation more suitable for safety-critical applications which need to ensure safety in all decision steps and may not always possess safe actions, e.g., robot control and autonomous driving. We propose a novel algorithm SUCBVI, which guarantees $\widetilde{O}(\sqrt{ST})$ step-wise violation and $\widetilde{O}(\sqrt{H^3SAT})$ regret. Lower bounds are provided to validate the optimality in both violation and regret performance with respect to $S$ and $T$. Moreover, we further study a novel safe reward-free exploration problem with step-wise violation constraints. For this problem, we design an $(\varepsilon,\delta)$-PAC algorithm SRF-UCRL, which achieves nearly state-of-the-art sample complexity $\widetilde{O}((\frac{S^2AH^2}{\varepsilon}+\frac{H^4SA}{\varepsilon^2})(\log(\frac{1}{\delta})+S))$, and guarantees $\widetilde{O}(\sqrt{ST})$ violation during the exploration. The experimental results demonstrate the superiority of our algorithms in safety performance, and corroborate our theoretical results.
翻译:在这份文件中,我们调查了一个新的安全强化学习问题,有步骤的违反限制。我们的问题与现有的工作不同,因为我们认为更严格的步骤违反限制,不假定存在安全行动,使我们的配方更适合安全关键应用,这些应用需要确保所有决策步骤的安全,而且可能并不总是拥有安全行动,例如机器人控制和自主驾驶。我们提出了一个新的SUCBVI算法,它保证美元(全局)和美元(SRCR-UCRL)的逐步违反和(全局)的违反。提供了较低的界限,以验证在美元和T$方面的最佳违规和遗憾业绩。此外,我们进一步研究一个新的安全无报酬的勘探问题,有步骤违反限制。为此,我们设计了一个美元(carepsilon,\delta)美元(PAC)的SRF-UCRL算法, 并提供了近于州级的样品复杂性 $(sqrettil{H3SAT}(S&reval_Sqral_%SQ_BAR_BAR_BAR_) 和(c_xxxxxxx) 保证在(SA_xxx)期间,(S&xxxxxxxxxxxx) 和(Sxxxxxxxxxxxx) 和(Sxxxxxxxxxxxx) 和(Sxxxxxxxxx) )结果。</s>