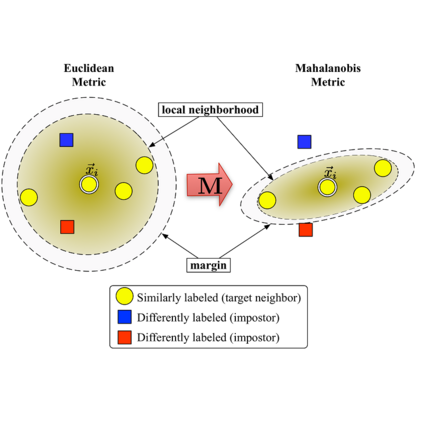
Recent studies show that, both explicit deep feature matching as well as large-scale and diverse training data can significantly improve the generalization of person re-identification. However, the efficiency of learning deep matchers on large-scale data has not yet been adequately studied. Though learning with classification parameters or class memory is a popular way, it incurs large memory and computational costs. In contrast, pairwise deep metric learning within mini batches would be a better choice. However, the most popular random sampling method, the well-known PK sampler, is not informative and efficient for deep metric learning. Though online hard example mining has improved the learning efficiency to some extent, the mining in mini batches after random sampling is still limited. This inspires us to explore the use of hard example mining earlier, in the data sampling stage. To do so, in this paper, we propose an efficient mini-batch sampling method, called graph sampling (GS), for large-scale deep metric learning. The basic idea is to build a nearest neighbor relationship graph for all classes at the beginning of each epoch. Then, each mini batch is composed of a randomly selected class and its nearest neighboring classes so as to provide informative and challenging examples for learning. Together with an adapted competitive baseline, we improve the state of the art in generalizable person re-identification significantly, by 25.1% in Rank-1 on MSMT17 when trained on RandPerson. Besides, the proposed method also outperforms the competitive baseline, by 6.8% in Rank-1 on CUHK03-NP when trained on MSMT17. Meanwhile, the training time is significantly reduced, from 25.4 hours to 2 hours when trained on RandPerson with 8,000 identities. Code is available at https://github.com/ShengcaiLiao/QAConv.
翻译:最近的研究显示,既明显深层特征匹配,又大规模和多样化的培训数据,都能够显著改善个人再识别的普及程度。然而,在大规模数据中学习深层匹配者的效率尚未充分研究。虽然以分类参数或类记忆学习是一种流行的方式,但需要大量记忆和计算成本。相比之下,在小型批次中进行双深深层的学习将是一个更好的选择。然而,最受欢迎的随机抽样方法,著名的PK取样器,并没有为深层次的计量学习带来信息和效率。尽管在线硬实例采矿在某种程度上提高了学习效率,但随机抽样后在小型批次中学习深层匹配者的效率仍然有限。这激励我们探索在数据取样阶段更早地使用硬示例采矿,但为了做到这一点,我们建议采用高效的小型批量取样方法,即称为图表取样(GS),用于大规模深入的计量学习。但基本想法是,在每开始深入学习时,所有类的RGRG4 4 4 都通过随机选择的班级和最接近的SM1,在经过培训的BS-1级中,通过经过培训的班级升级的25级和最接近的S-RMT-R1 级, 级,通过我们经过培训的升级的升级的升级的排序,在学习的排序中进行大幅的排序中进行大幅的排序的排序的排序的学习,从而提供高分级的排序的排序的排序的排序的排序的学习,提供。