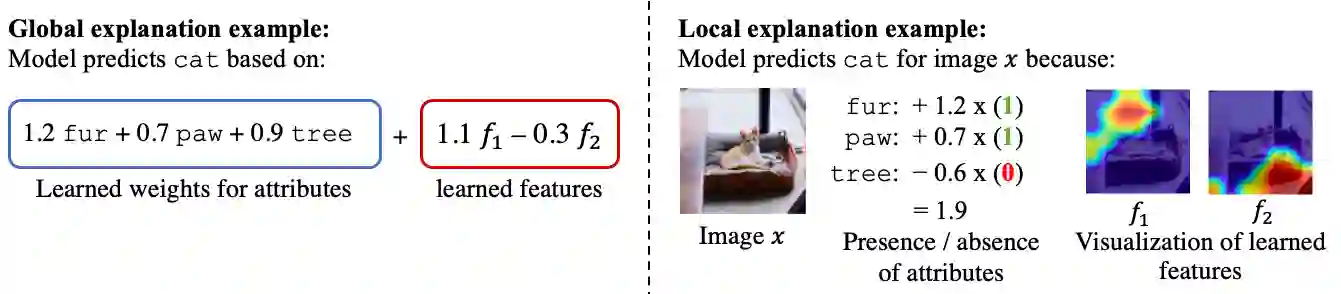
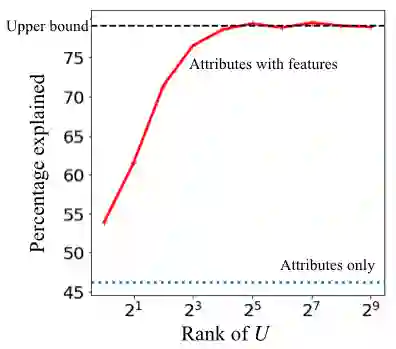
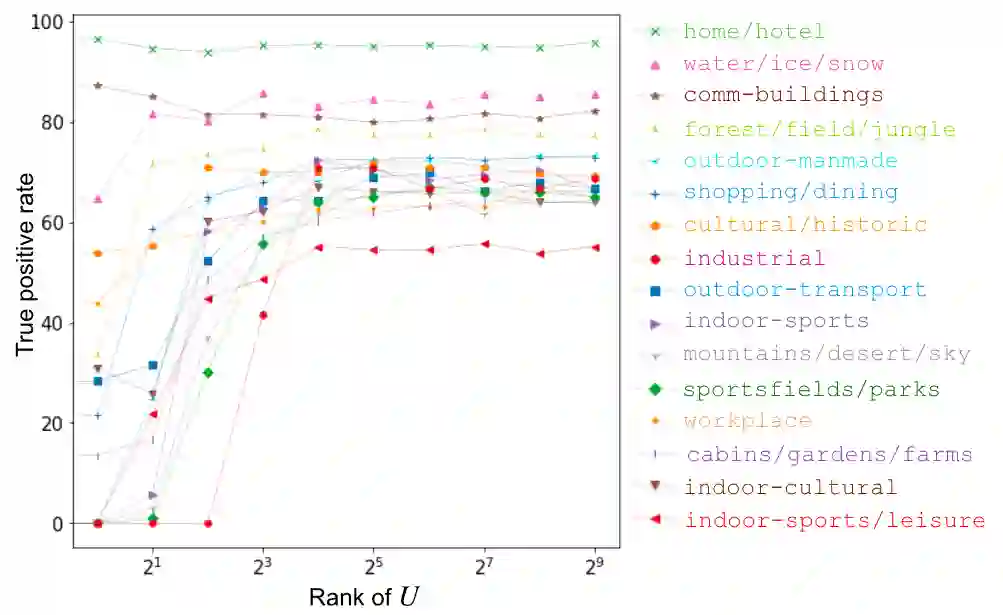
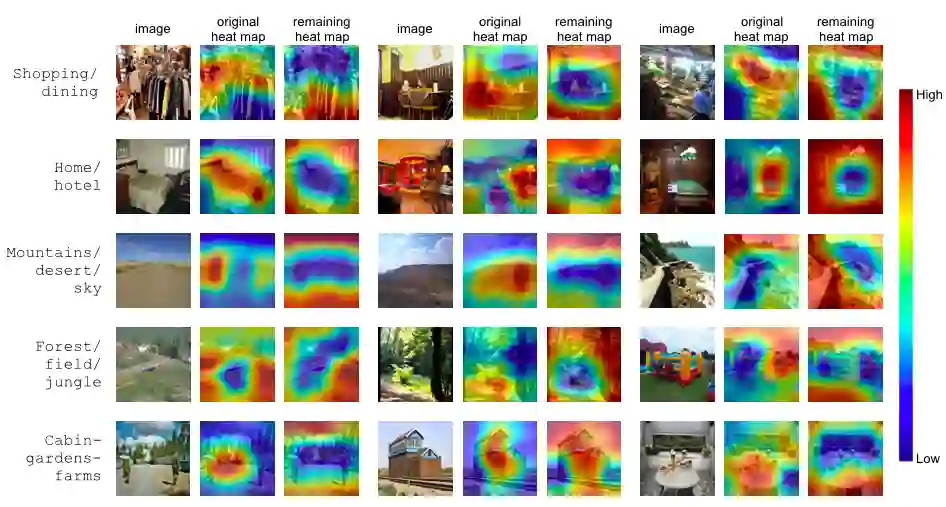
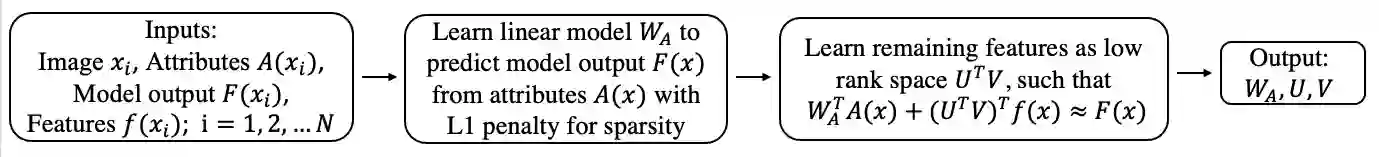Deep learning models have achieved remarkable success in different areas of machine learning over the past decade; however, the size and complexity of these models make them difficult to understand. In an effort to make them more interpretable, several recent works focus on explaining parts of a deep neural network through human-interpretable, semantic attributes. However, it may be impossible to completely explain complex models using only semantic attributes. In this work, we propose to augment these attributes with a small set of uninterpretable features. Specifically, we develop a novel explanation framework ELUDE (Explanation via Labelled and Unlabelled DEcomposition) that decomposes a model's prediction into two parts: one that is explainable through a linear combination of the semantic attributes, and another that is dependent on the set of uninterpretable features. By identifying the latter, we are able to analyze the "unexplained" portion of the model, obtaining insights into the information used by the model. We show that the set of unlabelled features can generalize to multiple models trained with the same feature space and compare our work to two popular attribute-oriented methods, Interpretable Basis Decomposition and Concept Bottleneck, and discuss the additional insights ELUDE provides.
翻译:过去十年来,深层次的学习模式在机器学习的不同领域取得了显著的成功;然而,由于这些模式的规模和复杂性,难以理解,因此很难理解这些模式。为了使其更易解释,最近的一些工作侧重于通过人文解释、语义属性解释深层神经网络的部分内容。然而,可能无法仅仅使用语义属性来完全解释复杂的模型。在这项工作中,我们提议用一套小的、无法解释的特征来充实这些属性。具体地说,我们开发了一个全新的解释框架ELUDE(通过Labelled和未加标签的 Decomposition进行探索),将模型的预测分为两个部分:一个是通过语义属性的线性组合来解释的,另一个是取决于一组非语义特征的。通过识别后一种特征,我们可以分析模型的“未加解释”部分,了解模型使用的信息。我们展示了一组未加标签的特征可以概括为同一特征所训练的多个模型,并将我们的工作与两种流行的直观和透视方法进行比较。