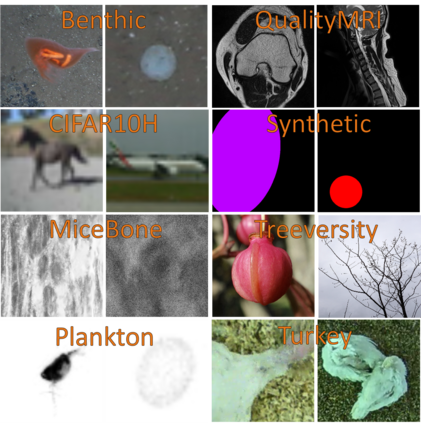
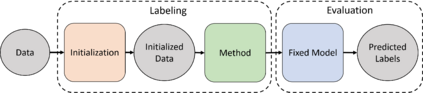
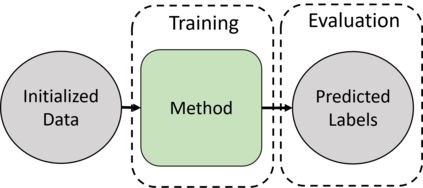
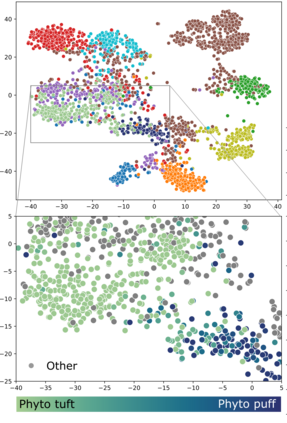
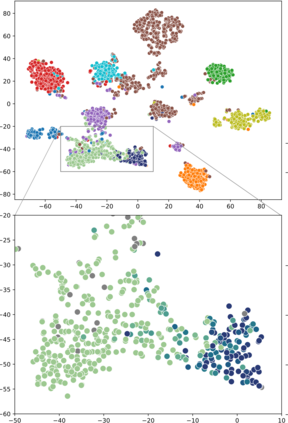
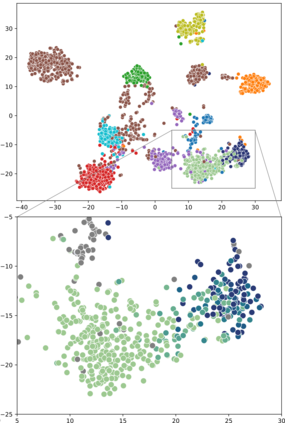
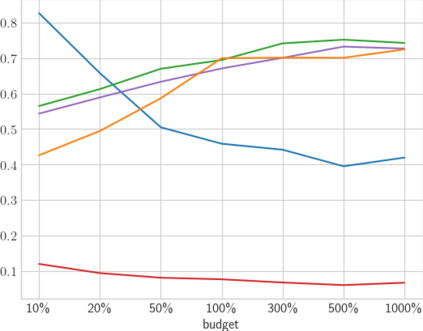
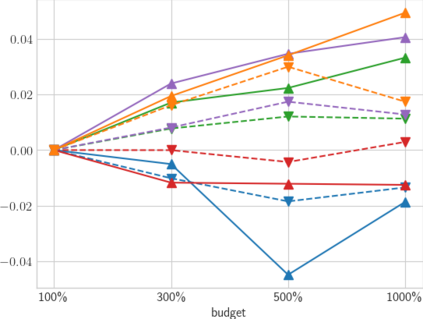
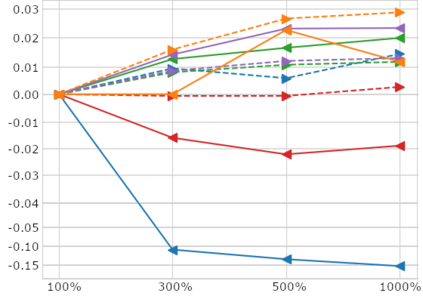
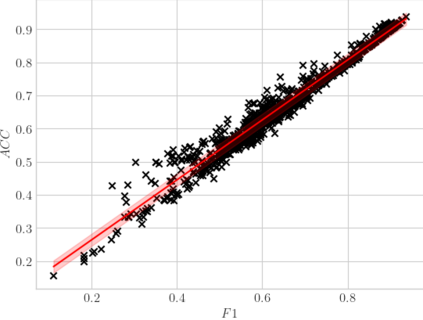
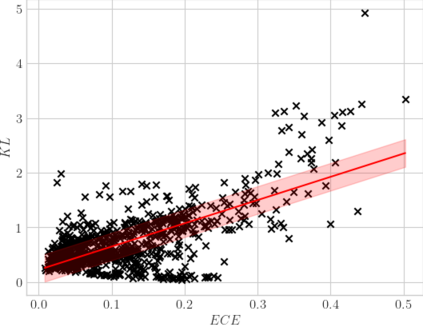
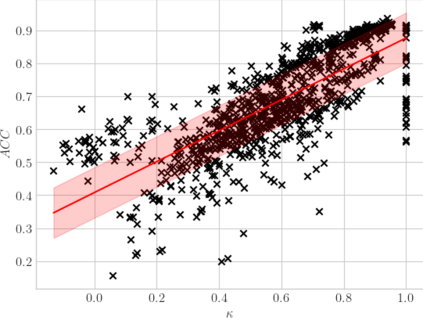
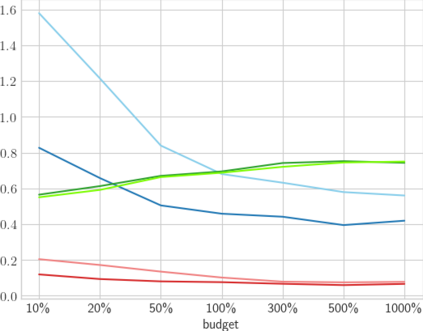
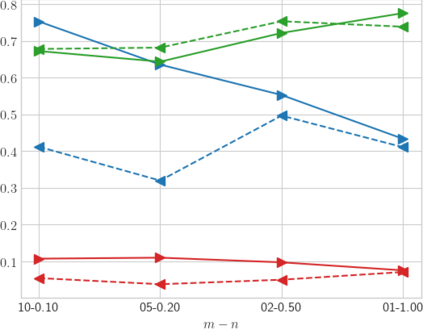
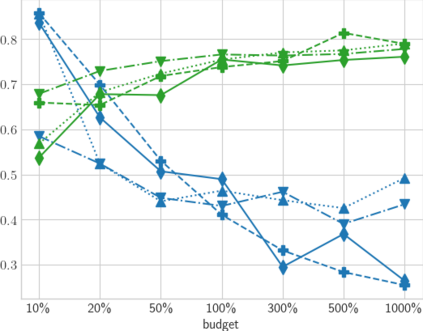
High-quality data is necessary for modern machine learning. However, the acquisition of such data is difficult due to noisy and ambiguous annotations of humans. The aggregation of such annotations to determine the label of an image leads to a lower data quality. We propose a data-centric image classification benchmark with nine real-world datasets and multiple annotations per image to investigate and quantify the impact of such data quality issues. We focus on a data-centric perspective by asking how we could improve the data quality. Across thousands of experiments, we show that multiple annotations allow a better approximation of the real underlying class distribution. We identify that hard labels can not capture the ambiguity of the data and this might lead to the common issue of overconfident models. Based on the presented datasets, benchmark baselines, and analysis, we create multiple research opportunities for the future.
翻译:现代机器学习需要高质量的数据。 但是,由于人类的杂音和模糊的描述,很难获取这些数据。 将这类说明汇总以确定图像的标签导致数据质量下降。 我们建议采用以数据为中心的图像分类基准,每个图像有9个真实世界数据集和多个说明,以调查和量化数据质量问题的影响。 我们侧重于以数据为中心的视角,询问如何提高数据质量。 在数千个实验中,我们显示多个说明可以更好地接近真实的底层分类分布。 我们发现硬标签无法捕捉数据的模糊性,这可能导致过分自信模式的常见问题。 根据所提供的数据集、基准基线和分析,我们为未来创造多种研究机会。