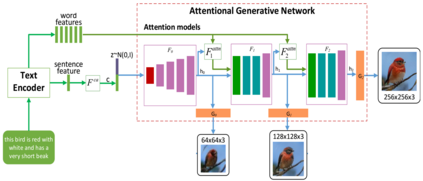
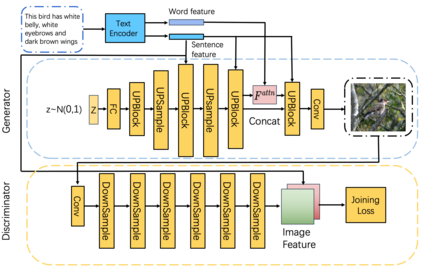
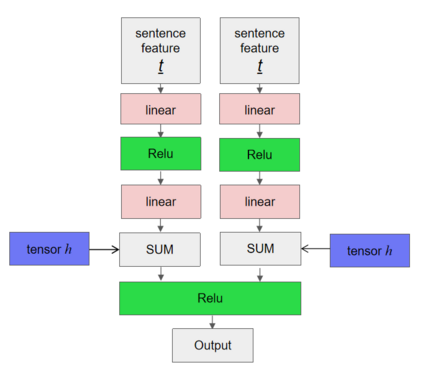
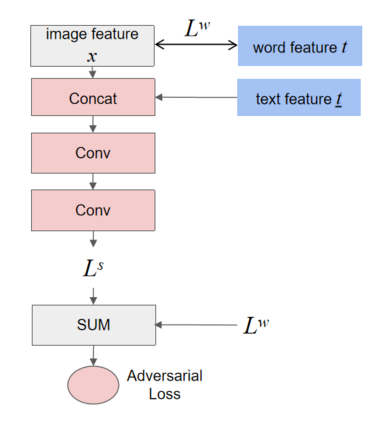
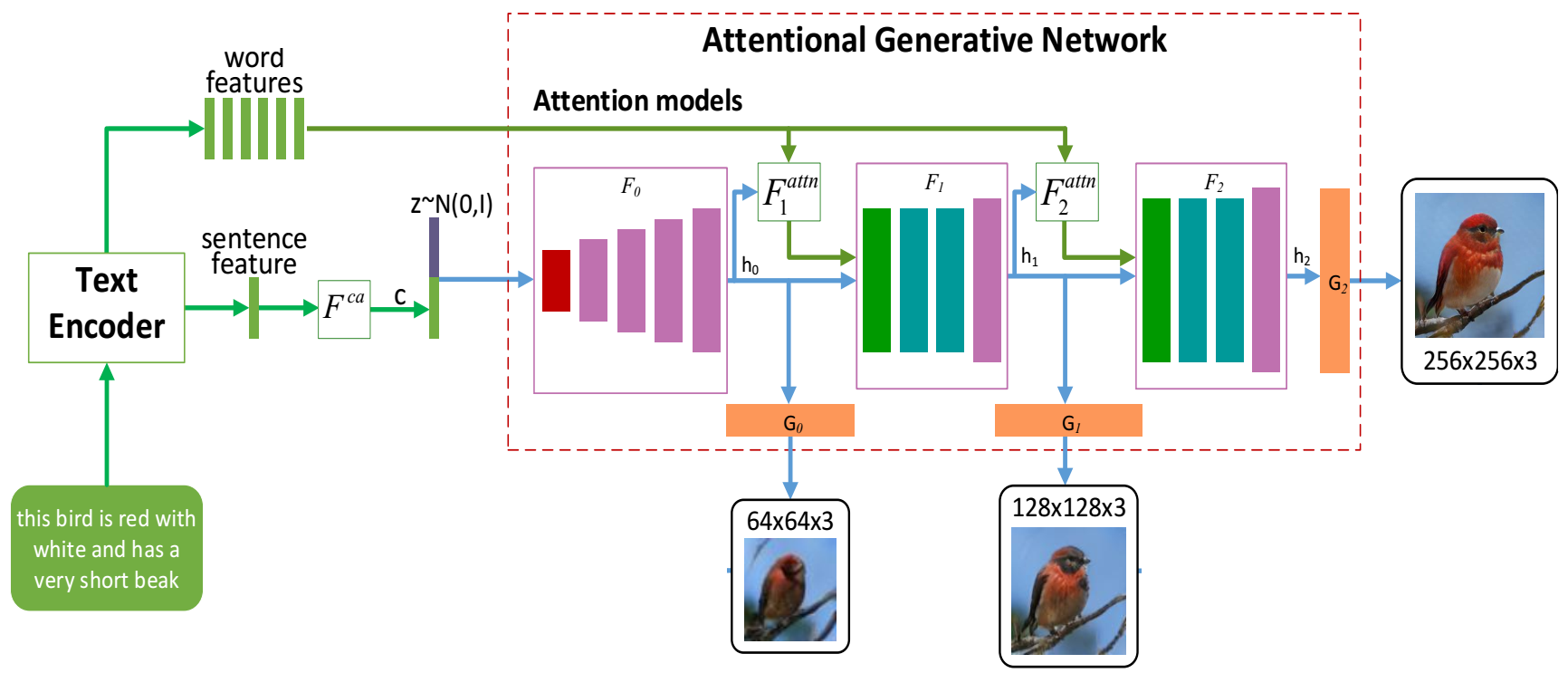
Synthesising a text-to-image model of high-quality images by guiding the generative model through the Text description is an innovative and challenging task. In recent years, AttnGAN based on the Attention mechanism to guide GAN training has been proposed, SD-GAN, which adopts a self-distillation technique to improve the performance of the generator and the quality of image generation, and Stack-GAN++, which gradually improves the details and quality of the image by stacking multiple generators and discriminators. However, this series of improvements to GAN all have redundancy to a certain extent, which affects the generation performance and complexity to a certain extent. We use the popular simple and effective idea (1) to remove redundancy structure and improve the backbone network of AttnGAN. (2) to integrate and reconstruct multiple losses of DAMSM. Our improvements have significantly improved the model size and training efficiency while ensuring that the model's performance is unchanged and finally proposed our SEAttnGAN. Code is avalilable at https://github.com/jmyissb/SEAttnGAN.
翻译:暂无翻译