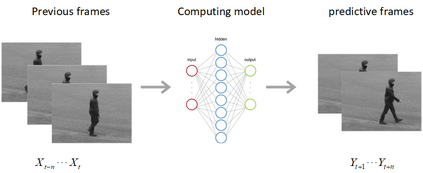
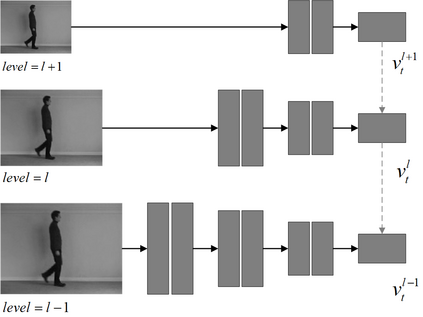
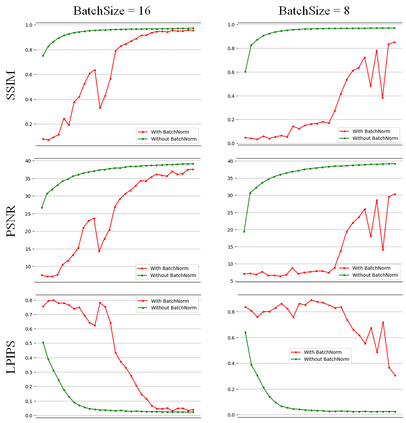
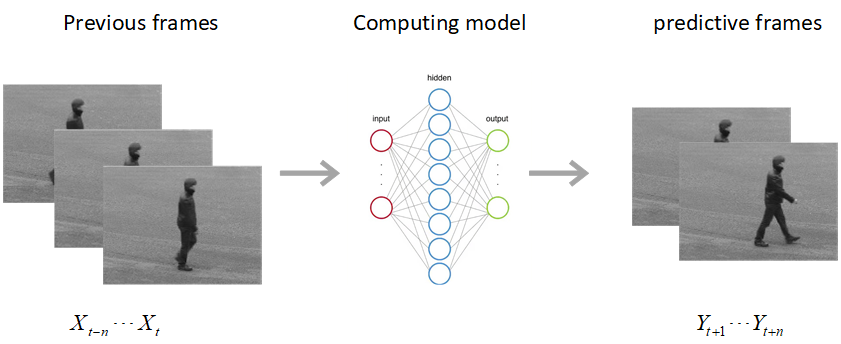
We are introducing a multi-scale predictive model for video prediction here, whose design is inspired by the "Predictive Coding" theories and "Coarse to Fine" approach. As a predictive coding model, it is updated by a combination of bottom-up and top-down information flows, which is different from traditional bottom-up training style. Its advantage is to reduce the dependence on input information and improve its ability to predict and generate images. Importantly, we achieve with a multi-scale approach -- higher level neurons generate coarser predictions (lower resolution), while the lower level generate finer predictions (higher resolution). This is different from the traditional predictive coding framework in which higher level predict the activity of neurons in lower level. To improve the predictive ability, we integrate an encoder-decoder network in the LSTM architecture and share the final encoded high-level semantic information between different levels. Additionally, since the output of each network level is an RGB image, a smaller LSTM hidden state can be used to retain and update the only necessary hidden information, avoiding being mapped to an overly discrete and complex space. In this way, we can reduce the difficulty of prediction and the computational overhead. Finally, we further explore the training strategies, to address the instability in adversarial training and mismatch between training and testing in long-term prediction. Code is available at https://github.com/Ling-CF/MSPN.
翻译:我们在此推出一个多尺度的视频预测预测模型,其设计受“预先编码”理论和“粗到精”方法的启发。作为一种预测编码模型,它通过自下而上和自上而下的信息流动相结合加以更新,这与传统的自下而上培训风格不同。它的优点是减少对输入信息的依赖,提高预测和生成图像的能力。重要的是,我们通过一个多尺度的方法实现了一个更高的神经神经元产生粗略预测(低分辨率),而较低的神经元则产生更精细的预测(高分辨率)。这与传统的预测编码框架不同,在传统的预测编码框架中,高层次预测神经元的活动会达到更高的水平。为了提高预测能力,我们将编码编码解码网络纳入LSTM结构,并在不同级别之间分享最后编码的高层次的测算性测算信息。此外,由于每个网络级别的产出是RGB图像(低分辨率),因此,一个较小的LSTM隐藏状态可以用来保留和更新必要的隐藏信息(高分辨率分辨率分辨率分辨率)。我们可以在长期的预测和复杂空间的测试中进一步减少我们进行不连续的、不连续和不连续的预测性分析的测试。