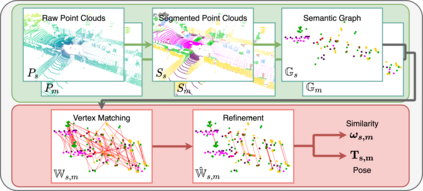
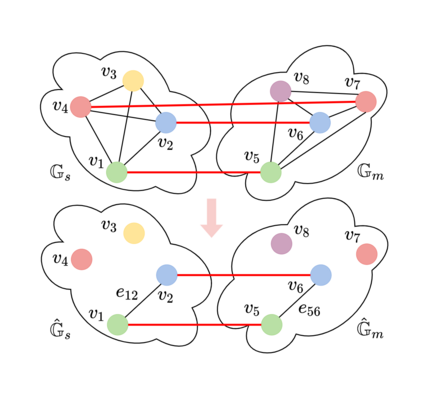
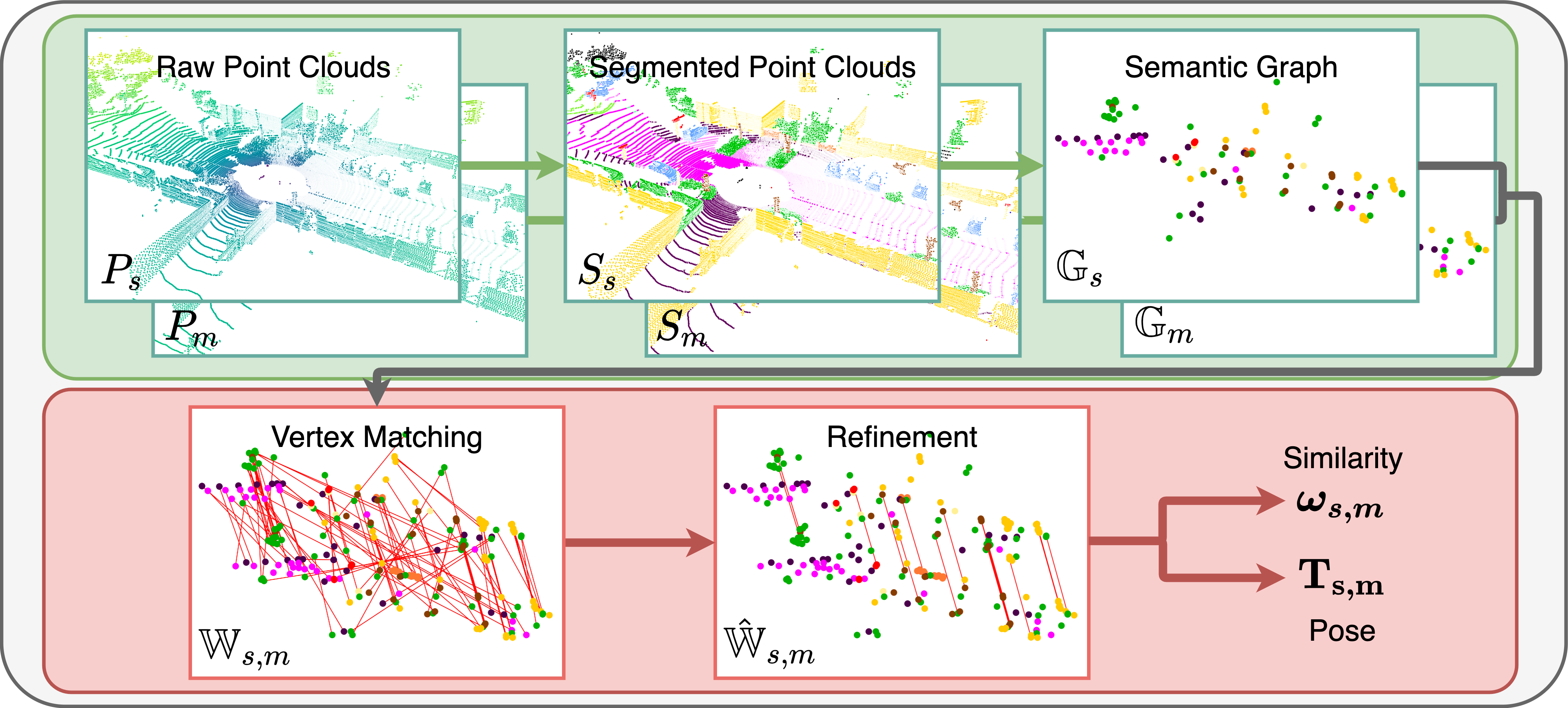
This paper is about extremely robust and lightweight localisation using LiDAR point clouds based on instance segmentation and graph matching. We model 3D point clouds as fully-connected graphs of semantically identified components where each vertex corresponds to an object instance and encodes its shape. Optimal vertex association across graphs allows for full 6-Degree-of-Freedom (DoF) pose estimation and place recognition by measuring similarity. This representation is very concise, condensing the size of maps by a factor of 25 against the state-of-the-art, requiring only 3kB to represent a 1.4MB laser scan. We verify the efficacy of our system on the SemanticKITTI dataset, where we achieve a new state-of-the-art in place recognition, with an average of 88.4% recall at 100% precision where the next closest competitor follows with 64.9%. We also show accurate metric pose estimation performance - estimating 6-DoF pose with median errors of 10 cm and 0.33 deg.
翻译:本文涉及使用以例分解和图形匹配为基础的LiDAR点云极强和轻量度本地化。 我们用三维点云作为完全连接的线性识别元件图, 每个顶点对应一个对象实例, 并编码其形状 。 最佳的顶点组合在图形上允许完全的 6- Degree- freeder (DoF) 进行估计, 通过测量相似度来确认位置 。 此表示非常简明, 将地图的大小压缩25倍, 与最新技术相比, 只需要 3kB 来代表1.4MB 激光扫描。 我们在SemaniticKITTI 数据集中验证了我们的系统的有效性, 我们在该数据集中实现了一种新的状态识别, 平均为 88.4% 的精确度记得, 下个最接近的比较器与64.9% 。 我们还展示了准确的度表情估计性能 - 估计 6-DF 形状与中位误为 10厘米和0.33德。