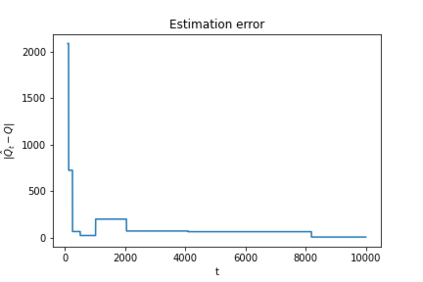
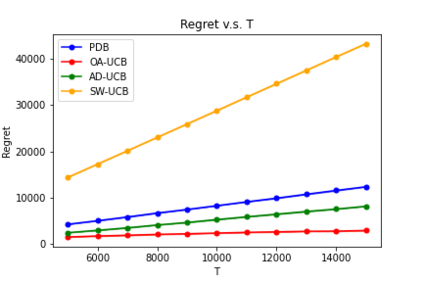
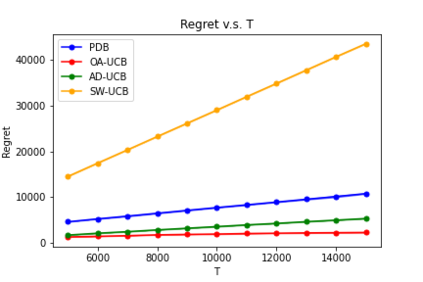
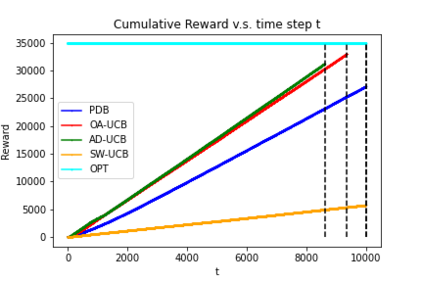
We consider a non-stationary Bandits with Knapsack problem. The outcome distribution at each time is scaled by a non-stationary quantity that signifies changing demand volumes. Instead of studying settings with limited non-stationarity, we investigate how online predictions on the total demand volume $Q$ allows us to improve our performance guarantees. We show that, without any prediction, any online algorithm incurs a linear-in-$T$ regret. In contrast, with online predictions on $Q$, we propose an online algorithm that judiciously incorporates the predictions, and achieve regret bounds that depends on the accuracy of the predictions. These bounds are shown to be tight in settings when prediction accuracy improves across time. Our theoretical results are corroborated by our numerical findings.
翻译:我们考虑的是带有Knapsack问题的非静态强盗。 每一次的结果分布都以非静态数量来缩放, 表明需求量的变化。 我们不是研究有限的非静态环境,而是调查对总需求量的在线预测如何使我们能够改进绩效保障。 我们显示, 没有任何预测, 任何在线算法都会产生直线以美元计价的遗憾。 相反, 在网上预测以美元计价时, 我们提议了一种网上算法, 明智地将预测纳入其中, 并实现取决于预测准确性的遗憾界限。 当预测准确性不断提高时, 这些界限在各种环境里显得很紧。 我们的理论结果得到了我们数字调查结果的证实。