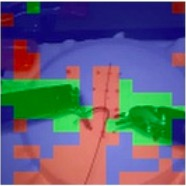
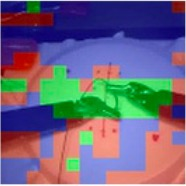
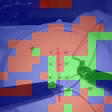
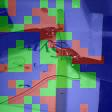
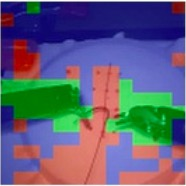
Automated video-based assessment of surgical skills is a promising task in assisting young surgical trainees, especially in poor-resource areas. Existing works often resort to a CNN-LSTM joint framework that models long-term relationships by LSTMs on spatially pooled short-term CNN features. However, this practice would inevitably neglect the difference among semantic concepts such as tools, tissues, and background in the spatial dimension, impeding the subsequent temporal relationship modeling. In this paper, we propose a novel skill assessment framework, Video Semantic Aggregation (ViSA), which discovers different semantic parts and aggregates them across spatiotemporal dimensions. The explicit discovery of semantic parts provides an explanatory visualization that helps understand the neural network's decisions. It also enables us to further incorporate auxiliary information such as the kinematic data to improve representation learning and performance. The experiments on two datasets show the competitiveness of ViSA compared to state-of-the-art methods. Source code is available at: bit.ly/MICCAI2022ViSA.
翻译:对外科手术技能的自动视频评估是协助年轻外科受训人员,特别是在资源贫乏地区的一项很有希望的任务。现有工作往往采用CNN-LSTM联合框架,以LSTMs对空间集合短期CNN特征的长期关系进行模型,然而,这种做法不可避免地忽视了诸如工具、组织和空间方面背景等语义概念之间的差别,从而阻碍了随后的时间关系建模。在本文件中,我们提议了一个新颖的技能评估框架,即视频语义隔离(VISA),它发现不同的语义部分,并把它们汇集到整个空间时空层面。明确发现语义部分提供了解释性可视化,有助于理解神经网络的决定。它还使我们能够进一步纳入辅助信息,如运动数据,以改进代表性学习和性能。关于两个数据集的实验显示VISA相对于最新方法的竞争力。源代码可查到:bit.ly/MICCAI2022VISA。