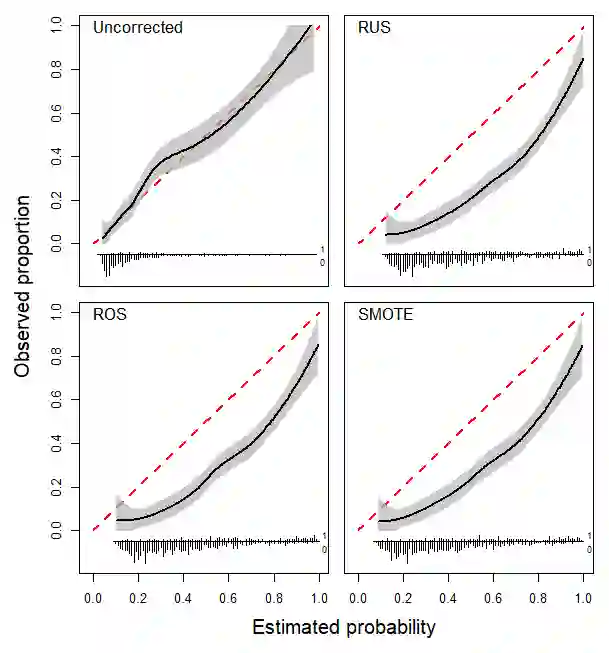
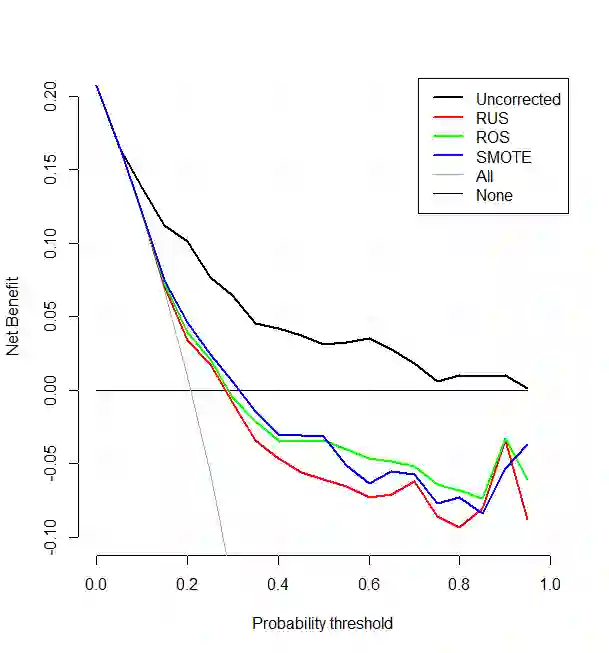
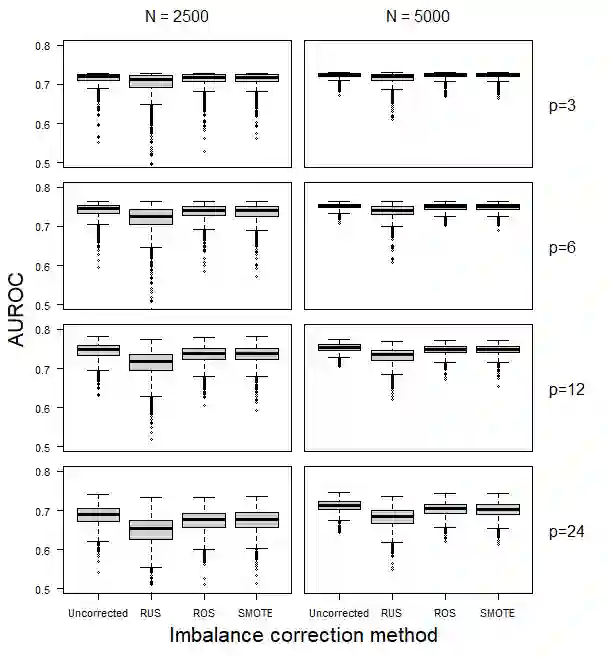
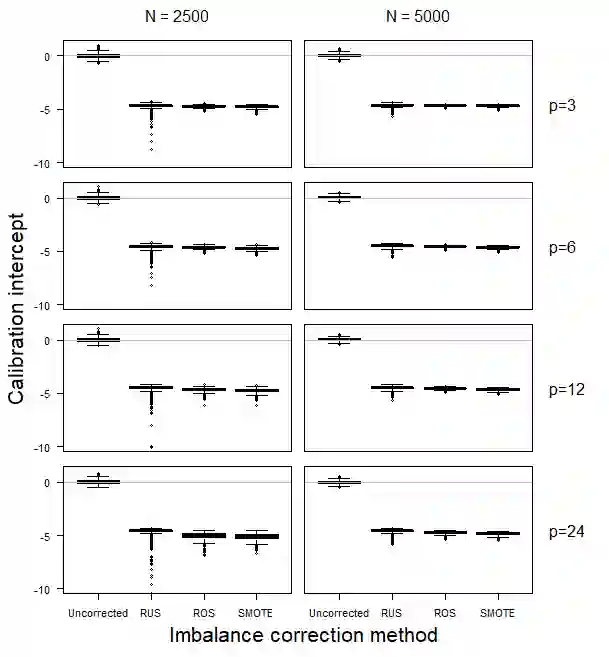
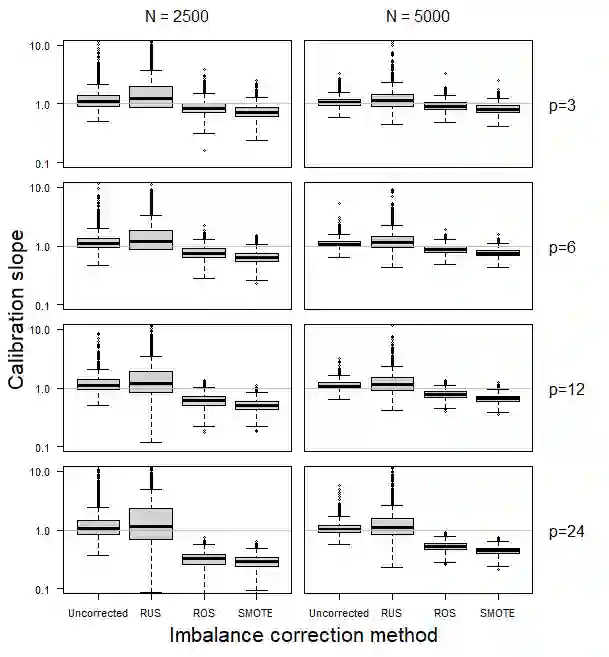
Methods to correct class imbalance, i.e. imbalance between the frequency of outcome events and non-events, are receiving increasing interest for developing prediction models. We examined the effect of imbalance correction on the performance of standard and penalized (ridge) logistic regression models in terms of discrimination, calibration, and classification. We examined random undersampling, random oversampling and SMOTE using Monte Carlo simulations and a case study on ovarian cancer diagnosis. The results indicated that all imbalance correction methods led to poor calibration (strong overestimation of the probability to belong to the minority class), but not to better discrimination in terms of the area under the receiver operating characteristic curve. Imbalance correction improved classification in terms of sensitivity and specificity, but similar results were obtained by shifting the probability threshold instead. Our study shows that outcome imbalance is not a problem in itself, and that imbalance correction may even worsen model performance.
翻译:我们从歧视、校准和分类的角度审查了不平衡纠正标准及受处罚(脊)后勤回归模型的性能的影响;我们利用蒙特卡洛模拟和卵巢癌诊断案例研究,对随机抽样、随机过度抽样和SMOTE进行了随机抽样、随机抽样和SMOTE调查;结果显示,所有不平衡纠正方法都导致校准差(严重高估属于少数类的可能性),但在接收器操作特征曲线下的地区没有更好的歧视; 平衡纠正在敏感度和特殊性方面改进了分类,但通过改变概率阈值获得了类似的结果; 我们的研究显示,结果不平衡本身不是问题,纠正不平衡甚至可能使模型性能恶化。